前面介绍了各种各样的超参数,这节课我们来看看如何用更加科学的方式来完成调试过程。
更新历史
- 2019.10.17: 完成初稿
调优过程 Tuning Process
神经网络的调优过程,实际上就是超参数的调试过程。超参虽多,但是有的超参要比其他超参更加重要,其中最重要的就是 学习率 $\alpha$。调整超参的原则主要有二:
- 使用随机参数值,不要使用 grid search,因为这样可以尝试数量更多的独立的学习率
- 由粗糙到精细,找到某个效果比较好的点后,在更小的区域继续随机参数取值
如何为超参数选择合适的范围?
主要有如下三种类别:
- 均匀随机:比如选取隐藏单元的数量,可以在 50~100 之间随机取值。其他的还有网络层数等
- 指数随机:比如学习率应该是 0.1/0.01/0.001,那就随机指数部分
- 特殊情况:比如 Adam 中的 $\beta$,取值是 0.9~0.999 之间,我们可以反向求 0.1~0.001 的指数随机,然后 1 减去它即可
如何搜索超参数?
一般来说有两种风格:
- 保姆风格:数据集非常大,但是计算资源较少,一次只能实验一个模型,每天调整一点点(因为不能同一时间试验大量模型)
- 平行模式:计算资源充足,可以同时测试多组超参数,最后选择效果最好的
两种方法的对比如下:
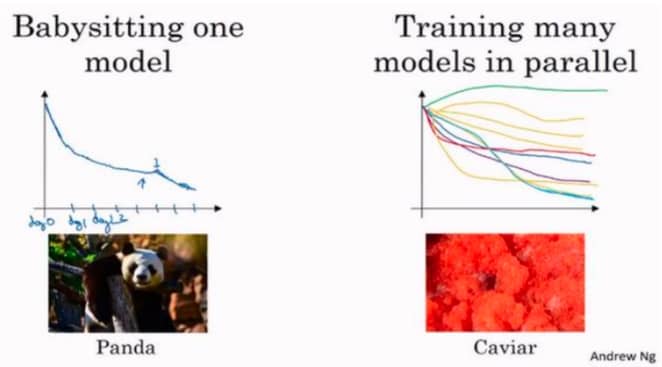
具体怎么选,要根据有多少计算资源决定。但是像广告和计算机视觉领域,数据太多,一般来说只能选择熊猫模式。
网络激活函数归一化 Normalizing Activations in a Network
Batch Normalization 对于深度学习来说是非常重要的一个思想,能够加快训练速度,降低超参数设置难度。

如上图所示,归一化的过程相当于把搜索空间从扁的拉伸到圆的,更有利于梯度下降学习。注意,这个过程发生在计算 z 和 a 之间(也就是在过激活函数之前,做一下归一化)
Batch Normalization 为什么有用?
主要原因有:
- 归一化是的搜索空间更加规整,可以加速梯度下降的速度
- 使权重比网络本身更滞后,更能经受的住变化,泛化能力更强
- 有轻微的正则化效果,类似于 dropout,给隐藏单元添加了噪音,迫使后面的单元不过分依赖任何一个隐藏单元
另外 Batch Normalization 一次只能处理一个 mini-batch 的数据。但是在测试的时候,我们可能需要对每一个样本逐一处理,就需要调整网络
测试时的 Batch Normalization 如何计算?
简单来说就是根据训练集来估算 $\mu$ 和 $\sigma^2$,一般来说深度学习框架都会包含,我们只要知道有这差别就可以。
Softmax Regression
前面我们处理的都是二分类,如果是多分类的话,我们就需要使用 Softmax Regression,最终得到的是一个向量,数学意义对应这个类别的概率,具体见下图:
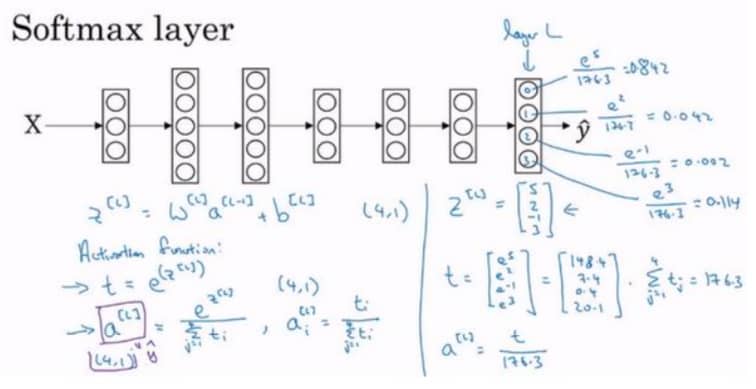
Softmax 回归实际上是 logistic 回归在多个类别上的推广,只有两个类别的 softmax 回归实际上相当于 logistic 回归。
如何训练 Softmax Regression?
关键点其实就在于,我们要用什么样的损失函数,一般来说,我们用这个:
$L(\hat{y},y)=-\Sigma_{j=1}^n y_j log\hat{y}_j$
简单来说,就是尽量让对应的类别的概率最大(也正是我们训练的目的),具体的推导就不再赘述,如果使用框架,这些基本上不需要特别操心。
深度学习框架 Deep Learning Frameworks
现在框架很多,选择框架的标准如下:
- 便于编程,包括开发、迭代以及上线到生产系统
- 运行速度
- 开源
截止 2019.10 月,目前的趋势是学术界 PyTorch,工业界 Tensorflow,其他的目前如果不是特殊偏好,可以暂缓。
Tensorflow
Tensorflow 的学习可以参考我之前的课程笔记 【CS20-TF4DL】00 课程概览,这里同样不再展开