上节课我们对卷积神经网络有了基本的了解,这次我们来看下在这个领域中的而一些经典工作。
更新历史
- 2019.10.20: 完成初稿
经典网络 Classic Networks
这一节主要会介绍 LeNet-5, AlexNet 和 VGGNet。
LeNet-5
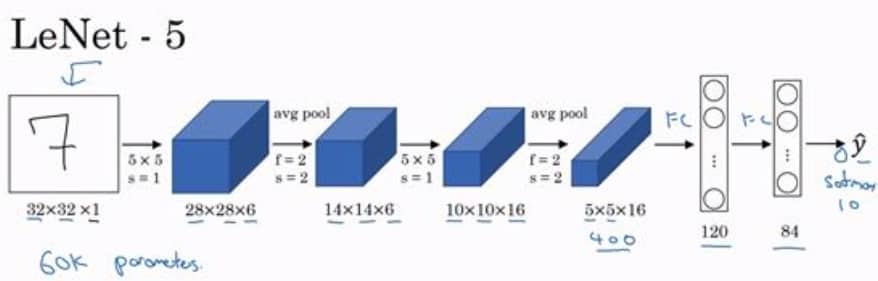
约 6 万个参数,随着网络越来越深,图像的高度和宽度在缩小,但通道数量在增加。这种卷积层+池化层的模块,以及最后与全连接层相连的形式,是非常常见的套路。另外,在原始论文中,激活函数是 sigmoid 和 tanh,而不是现在广泛使用的 ReLU。
AlexNet
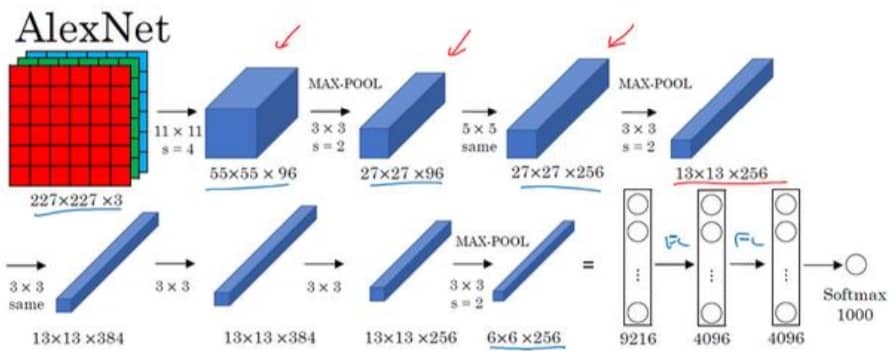
整体的套路与 LeNet-5 相似,但 AlexNet 包含约 6000 万个参数,是前者的一千倍,另外使用了 ReLU 激活函数。
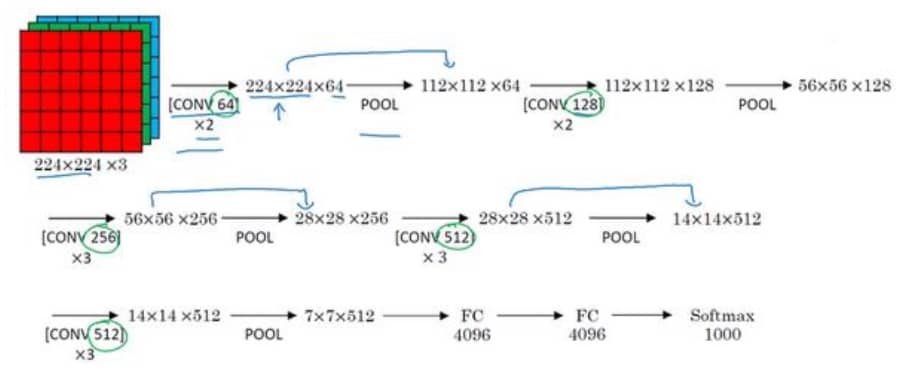
VGG-16
VGG 网络没有那么多个超参,其核心是卷积层。但是因为网络比较深,所以参数非常多,大约有 1.38 亿个参数(比 AlexNet 又多了一倍多)。有趣的地方在于,VGG-16 的结构并不复杂,比较好设计。
残差网络 Residual Networks(ResNets)
因为存在梯度消失和梯度爆炸的问题,神经网络是很难变得更深的。但是我们通过跳跃连接(Skip Connection)可以将某一层的激活反馈给更深层的网络,继而构建出可以超过 100 层的 ResNets。具体如下图所示:
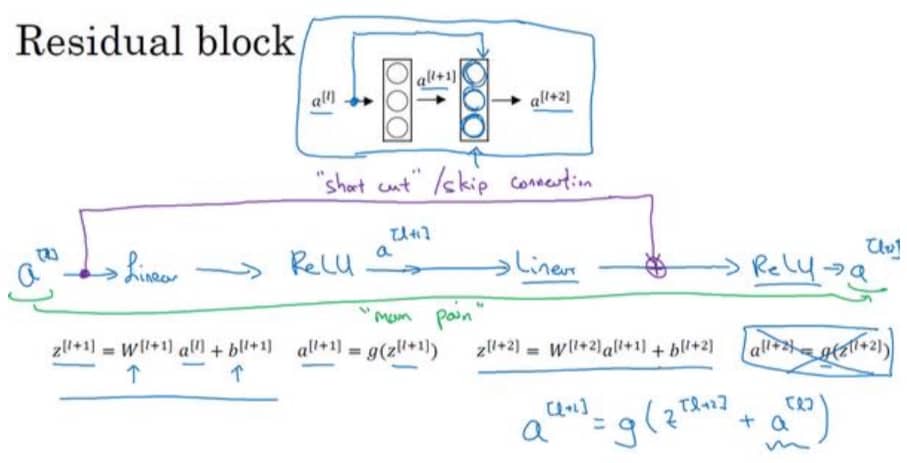
我们可以看到 $a^{[l]}$ 经过紫色的捷径直接跳过了下一层,这就是跳跃连接。我们把网络完整画出来,如下图所示:
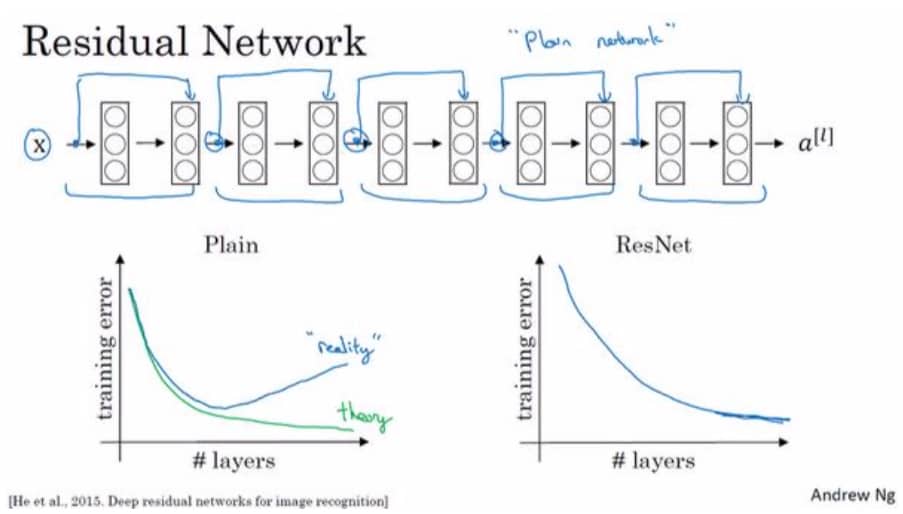
残差网络的优势在于随着层数增加,训练误差总是会下降的,而不会因为梯度消失或爆炸,使得误差不降反增。
为什么残差网络有用?
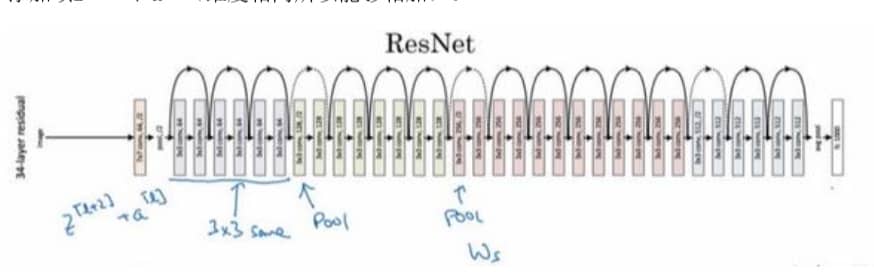
简单来说,是因为残差块学习恒等函数非常容易,网络的性能甚至会提升。另外把一个普通的网络改造成残差网络也很简单,如下图所示:
1x1 卷积的奥秘?
1x1 的卷积(有时也被称为 Network in Network)远不止是一个数字,你可以理解为对整个图像的任何一个位置都使用同一个全连接层,达到参数共享和网络压缩的效果,更重要的是,它给神经网络添加了一个非线性函数,能够减少或保持输入层中通道数量不变。

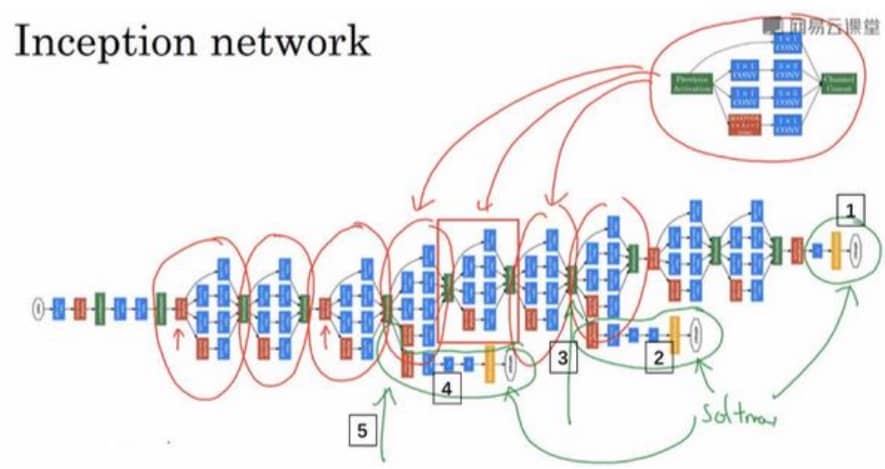
Inception Network
前面的诸多模型,我们至少需要选择过滤器的大小,比如是 1x1,还是 3x3,还是 5x5,还有要不要添加池化层。Inception 网络的作用在于,可以自动进行选择,虽然网络因此变得复杂,但是效果非常不错。那么 Inception 是如何做到的呢?其实也比较粗暴,我把各种参数都加进来,后面再进行权重调整不就好了吗?(很有谷歌大力出奇迹的风格,见下图)
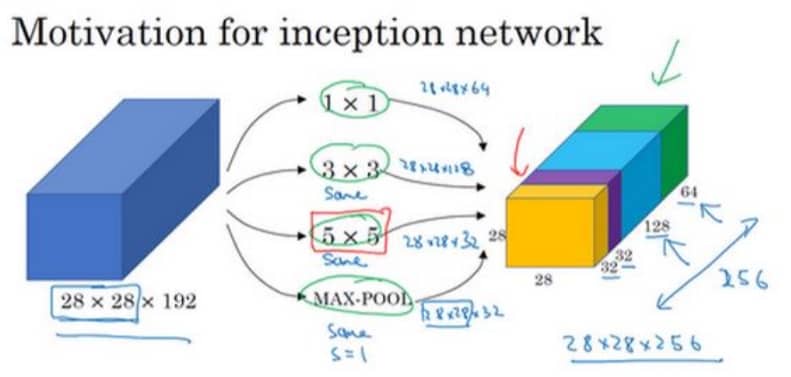
光看这个图就可以知道,Inception 的最大问题在于计算成本。这个时候我们就可以利用 1x1 的卷积来构建瓶颈层,从而大大降低计算成本。
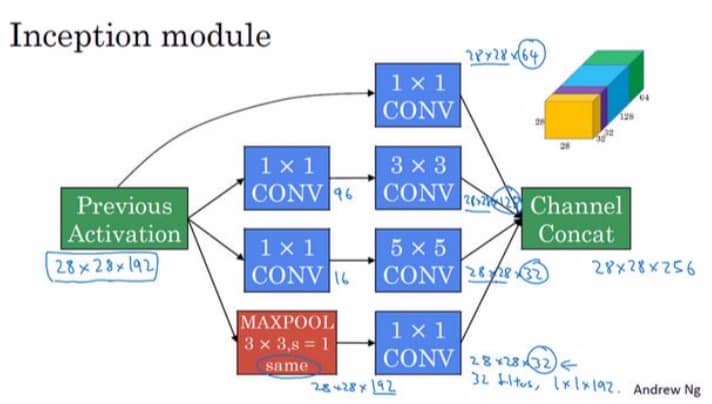
构建 Inception 模块
Inception 模块的构建很简单,我们只要注意用好 1x1 即可,如下图所示
构建 Inception 网络
我们把 Inception 模块花式组合起来,就得到了 Inception 网络
另外,在实际工作中多多利用预训练模型和数据扩充,能够收到很好的效果。原则上来说,数据越多,需要人工调整的部分就越少。