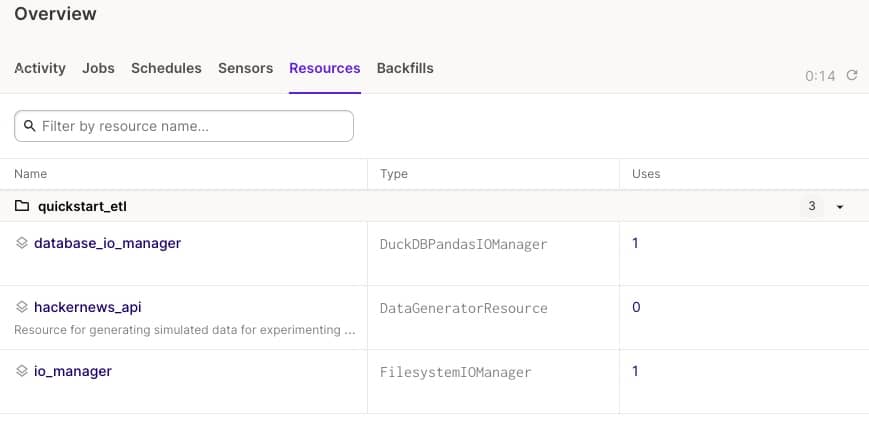
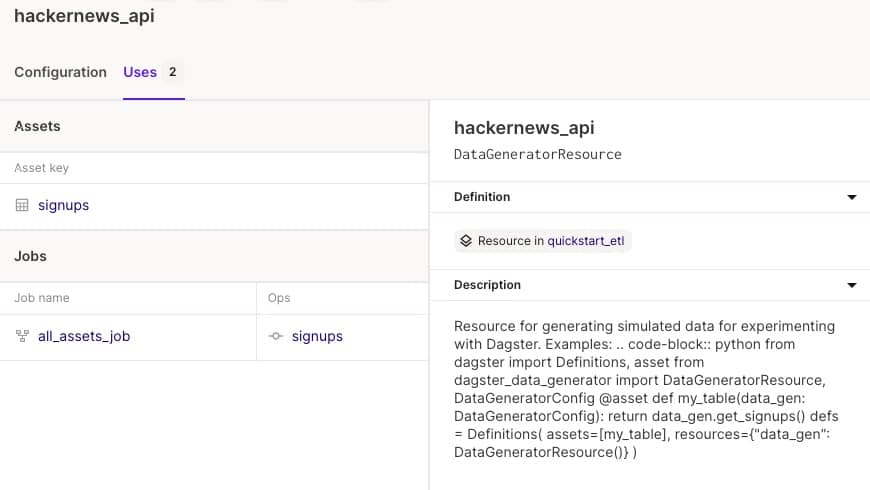
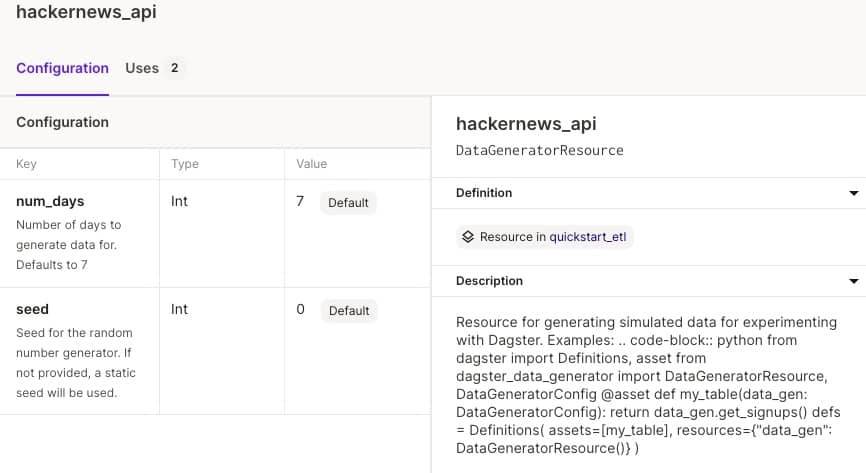
# 安装成功后输出 > Downloading example 'quickstart_etl'. This may take a while. > Success! Created dagster-etl-demo at /Users/wangda/Documents/Gitee/dagster-etl-demo/.
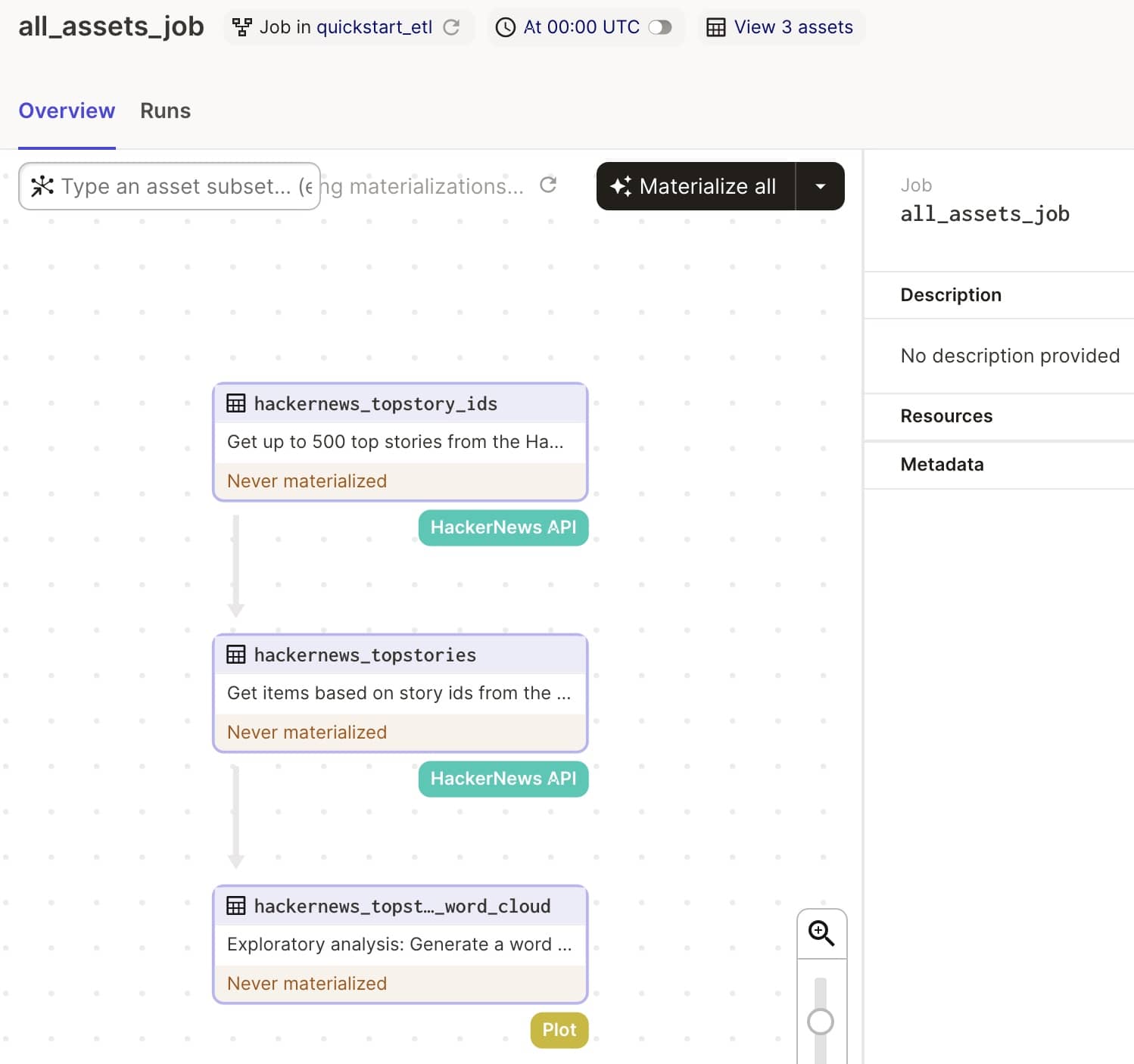
# 通过 @asset 声明是一个资产, -> 用来表示返回的类型 @asset(group_name="hackernews", compute_kind="HackerNews API") defhackernews_topstory_ids() -> List[int]: """Get up to 500 top stories from the HackerNews topstories endpoint. 通过 API 获取 Top 500 的新闻 API Docs: https://github.com/HackerNews/API#new-top-and-best-stories """ newstories_url = "https://hacker-news.firebaseio.com/v0/topstories.json" # 访问 url 并拿到 JSON 返回,最后变成一个 List[int] 的数组 top_500_newstories = requests.get(newstories_url).json() return top_500_newstories
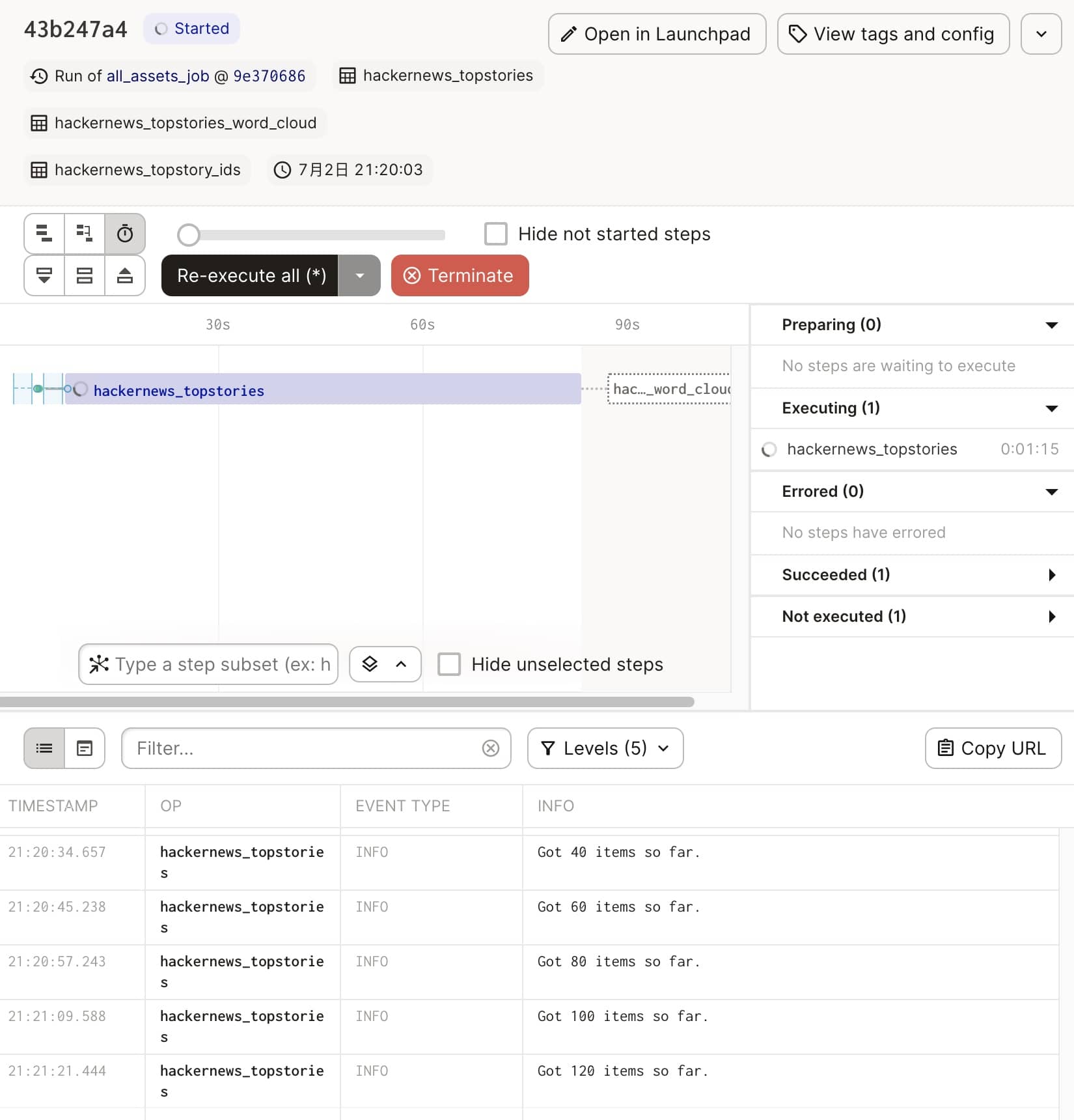
# 这里的参数是 hackernews_topstory_ids,表示依赖该资产,最终得到一个 pd.DataFrame # context 是一个资产上下文,传递信息和输出日志 @asset(group_name="hackernews", compute_kind="HackerNews API") defhackernews_topstories( context: AssetExecutionContext, hackernews_topstory_ids: List[int] ) -> pd.DataFrame: """Get items based on story ids from the HackerNews items endpoint. It may take 1-2 minutes to fetch all 500 items. 从 HackerNews 获取具体的数据 API Docs: https://github.com/HackerNews/API#items """ results = [] for item_id in hackernews_topstory_ids: # 访问 url 并拿到 JSON 返回,放到 DataFrame 中 item = requests.get(f"https://hacker-news.firebaseio.com/v0/item/{item_id}.json").json() results.append(item) # 每 20 条输出一条日志,可以在 Web UI 中查看 if len(results) % 20 == 0: context.log.info(f"Got {len(results)} items so far.")
df = pd.DataFrame(results)
# Dagster supports attaching arbitrary metadata to asset materializations. This metadata will be # shown in the run logs and also be displayed on the "Activity" tab of the "Asset Details" page in the UI. # This metadata would be useful for monitoring and maintaining the asset as you iterate. # Read more about in asset metadata in https://docs.dagster.io/concepts/assets/software-defined-assets#recording-materialization-metadata context.add_output_metadata( { "num_records": len(df), "preview": MetadataValue.md(df.head().to_markdown()), } ) return df
# 最后输出一个 bytes 序列,就是最终的图像,compute_kind 表示计算类型,可以自己指定 @asset(group_name="hackernews", compute_kind="Plot") defhackernews_topstories_word_cloud( context: AssetExecutionContext, hackernews_topstories: pd.DataFrame ) -> bytes: """Exploratory analysis: Generate a word cloud from the current top 500 HackerNews top stories. Embed the plot into a Markdown metadata for quick view. Read more about how to create word clouds in http://amueller.github.io/word_cloud/. """ stopwords = set(STOPWORDS) stopwords.update(["Ask", "Show", "HN"]) titles_text = " ".join([str(item) for item in hackernews_topstories["title"]]) titles_cloud = WordCloud(stopwords=stopwords, background_color="white").generate(titles_text)
# Generate the word cloud image plt.figure(figsize=(8, 8), facecolor=None) plt.imshow(titles_cloud, interpolation="bilinear") plt.axis("off") plt.tight_layout(pad=0)
# Save the image to a buffer and embed the image into Markdown content for quick view buffer = BytesIO() plt.savefig(buffer, format="png") image_data = base64.b64encode(buffer.getvalue()) md_content = f"})"
# Attach the Markdown content as metadata to the asset # Read about more metadata types in https://docs.dagster.io/_apidocs/ops#metadata-types context.add_output_metadata({"plot": MetadataValue.md(md_content)})
File "/Users/wangda/Dev/venvs/xsignal39/lib/python3.9/site-packages/dagster/_daemon/cli/__init__.py", line 82, in _daemon_run_command controller.check_daemon_loop() File "/Users/wangda/Dev/venvs/xsignal39/lib/python3.9/site-packages/dagster/_daemon/controller.py", line 296, in check_daemon_loop self.check_daemon_heartbeats() File "/Users/wangda/Dev/venvs/xsignal39/lib/python3.9/site-packages/dagster/_daemon/controller.py", line 265, in check_daemon_heartbeats raise Exception("Stopped dagster-daemon process due to thread heartbeat failure") Exception: Stopped dagster-daemon process due to thread heartbeat failure 2023-07-02 23:39:27 +0800 - dagster - INFO - Shutting down Dagster services... 2023-07-02 23:39:27 +0800 - dagster - INFO - Dagster services shut down.
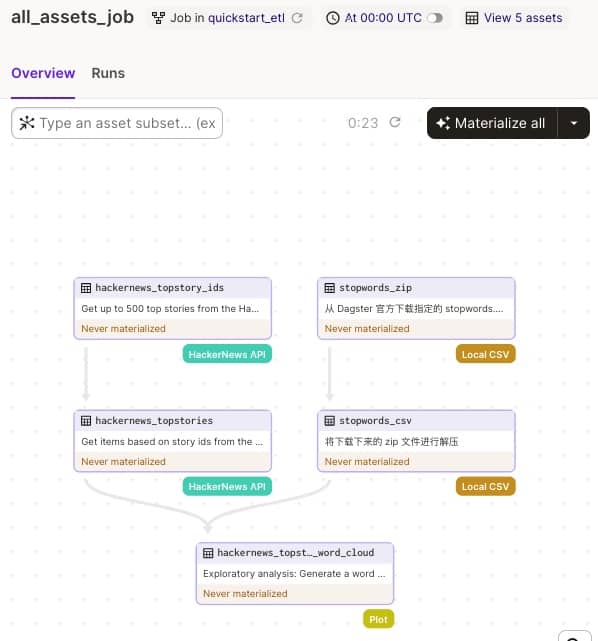
# 用 non_argument_deps 把相关资产串起来 @asset(group_name="hackernews", compute_kind="Plot", non_argument_deps={"stopwords_csv"}) defhackernews_topstories_word_cloud( context: AssetExecutionContext, hackernews_topstories: pd.DataFrame ) -> bytes: """Exploratory analysis: Generate a word cloud from the current top 500 HackerNews top stories. Embed the plot into a Markdown metadata for quick view. Read more about how to create word clouds in http://amueller.github.io/word_cloud/. """ #stopwords = set(STOPWORDS) #stopwords.update(["Ask", "Show", "HN"]) with open("data/stopwords.csv", "r") as f: stopwords = {row[0] for row in csv.reader(f)} titles_text = " ".join([str(item) for item in hackernews_topstories["title"]]) titles_cloud = WordCloud(stopwords=stopwords, background_color="white").generate(titles_text)