了解了基础的 python 和数学知识,我们现在就可以来学习神经网络了。
更新历史
- 2019.10.14: 完成初稿
神经网络的表示 Neural Network Representation
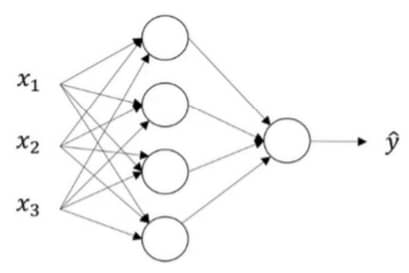
上图就是一个包含一个隐层的神经网络,其中:
- 输入层:x1, x2, x3
- 隐藏层:中间的 4 个节点
- 输出层:最后 1 个节点,负责产生预测值
一般来说,输入层不算一个标准的层,所以会把上面的网络称为一个两层的神经网络,这里的每个节点都是带有 w 和 b 这样的参数的。
计算神经网络的输出 Computing a Neural Network’s output)
简单来说,用下图就可以总结:
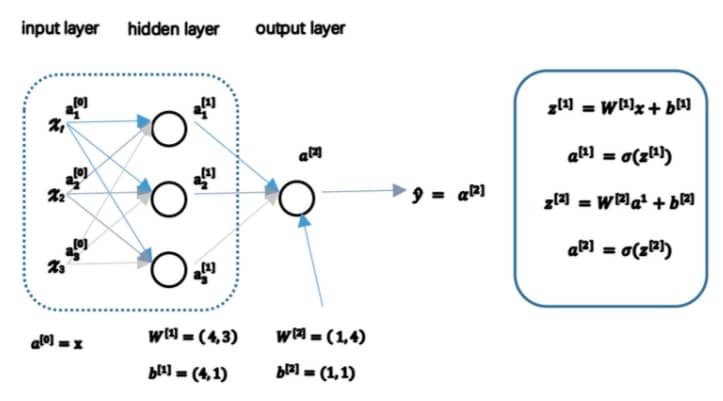
实际进行计算时,我们会使用上一节课介绍的向量化的方式,用矩阵进行运算。
激活函数 Activation functions
tanh 函数或者双曲正切函数总体上都优于 sigmoid 函数,tanh 函数可以看作是 sigmoid 向下平移和伸缩后的结果,其值域在 -1 和 1 之间,平均值更接近 0 而不是 0.5。但是在二分类中,我们希望输出介于 0 和 1,而不是 -1 和 1 之间,所以还是使用 sigmoid 函数。
sigmoid 和 tanh 的共同确实是在 z 特别大/小的时候,导数的梯度会特别小,梯度下降速度会变慢,这也就意味着更多的迭代次数和更长的训练时间。
选择激活函数的经验法则:
- 二分类问题:输出层 sigmoid,其他都是 Relu
- tanh 非常优秀,几乎适合所有场合
- Relu 是最常用的默认函数,如果不确定用哪个激活函数,用就完事儿
为什么需要非线性激活函数
简单来说,用线性激活函数得到的是线性组合,那么直接用 LR 就可以,所以无论如何,用非线性就完事儿
激活函数的导数 Derivatives of activation functions
四种常见激活函数的导数
Sigmoid
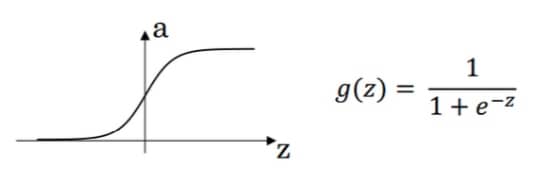
在神经网络中
可以看到这个求导的计算时非常简单的
Tanh
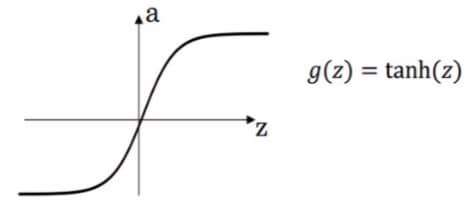
在神经网络中
Rectified Linear Unit(Relu)

可以看到导数的计算直接是定值,更好计算。一般来说 z 为 0 的时候给定导数为 1 或 0(但一般很少见)
Leaky linear unit(Leayky ReLU)
函数图像见上一节,求导结果为
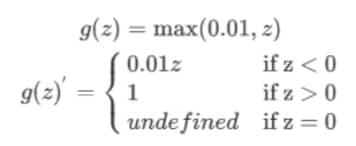
通常在 z 为 0 的时候给定导数为 1 或 0.01(但一般很少见)
随机初始化 Random Initialization
训练神经网络时,权重随机初始化非常重要,到底有多重要呢?如果都是 0,那么根本没办法训练,对于第一层和第二层的 w 和 b,可以用如下代码进行初始化:
1 | w1 = np.random.randn(2,2) * 0.01 |
如果用了 tanh 或 sigmoid 激活函数的话,如果数值波动太大,会导致经过激活函数后的值接近 0 或接近 1,学习速度很慢,所以我们要在参数上乘以一个 0.01