这一讲我们来看看 CNN,关于 CNN 其实前面 CS20 和 CS230 都有比较详细介绍,这里主要看看 PyTorch 如何快速实现。
更新历史
- 2019.11.07: 完成初稿
二维卷积层
二维卷积层一般用来处理图像数据,这里的核心函数是处理矩阵做卷积操作的,对应 Tensorflow 就是 conv2d 之类的,框架上都差不多在,主要命名差别。理论和概念就不提了,直接看代码:
注:深度学习中的卷积运算实际上是互相关运算,因为是学习出来的,不影响最终结果。二维卷积层输出的二维数组被称为特征图(feature map),影响某一点的全部区域叫做感受野(receptive field)
另外一对重要的概念是 Padding 和 Stride,主要影响输出的矩阵大小,需要重点理解下。
多输入/输出通道
简单来说,输入数据有多少个通道,我们的卷积核就也需要同样多的通道,这样才能一一对应处理。简单来说,就是各个通道和各个通道的卷积核做乘法,然后再把相同位置的结果加起来,如下图所示
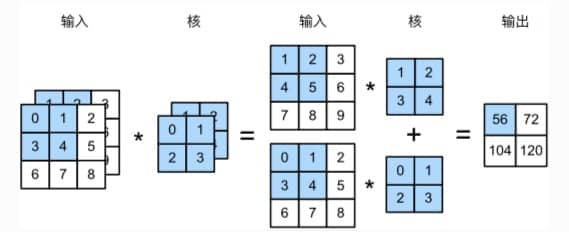
另外一个值得一提的就是 1x1 的卷积层(重要概念),可以看做是全连接层。通常用来调整网络层之间的通道数,并控制模型复杂度。相关代码参考
池化层
主要为了缓解卷积层对位置的过度敏感性,常用的是最大池化层,也有用平均池化层的,同样涉及 Padding 和 Stride 的问题。在处理多通道数据时,会对每个输入通道分别池化,这一点和卷积层的相加不一样了。池化层无法通过类似 1x1 的技巧改变通道数,只是一个简单的调整,也不涉及任何参数的学习。
这部分代码比较简单,不再专门列出。
LeNet
非常经典的网络结构,具体不介绍了,直接贴个结构图:
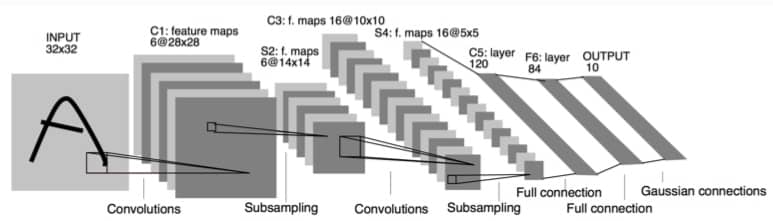
然后直接上代码:
AlexNet
2012 年 AlexNet 在 ImageNet 2012 图像识别挑战赛上一鸣惊人,证明了学习到的特征可以超越手工特征,结构如下:
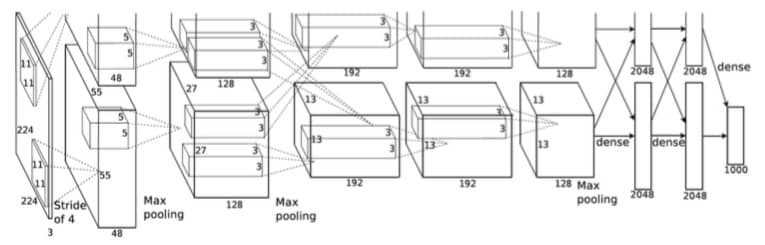
与 LeNet 的差别为:
- 总共 8 层,5 层卷积,2 层全连接,输出层也是全连接。卷积的窗口形状 从 11x11 到最后的 3x3
- 使用 ReLU 而非 Sigmoid 激活函数
- 使用 Dropout
- 使用数据增强来缓解过拟合问题
这里我们实现的是一个简化版本,用 CPU 训练时间比较长(你说我为什么会知道,因为我就是用 CPU 训练的啊!)
VGG
AlexNet 取得了很不错的成绩,但问题在于这个过程太过于经验化,我们没办法借鉴太多经验设计其他网络(这并不代表 AlexNet 不行,相反,更是很伟大的突破)。而 VGG 就提出可以通过重复使用简单的基础块来构建深度模型。
VGG 块的组成规律是:连续使用多个相同的 padding 为 1,kernel size 为 3x3 的卷积层后,接上一个 stride 为 2,kernel 为 2x2 的最大池化层。卷积层保持输入的尺寸不变,而池化层则对其减半。
具体参考下面代码,注意我因为机器限制,轮数为 1:
NiN
NiN 是网络中的网络,使用的窗口形状为 11x11, 5x5, 3x3,每个 NiN 块后接一个 stride 2,窗口 3x3 的最大池化层。
最大的不同时 NiN 去掉了 AlexNet 的最后 3 个全连接层,用输出通道数等于标签类别数的 NiN 块,然后用全局平均池化并直接用于分类,可以显著减小模型参数尺寸,缓解过拟合,但是训练时间一般要增加。
具体参考代码,注意我因为机器限制,轮数为 1:
GoogLeNet
GoogLeNet 在 2014 年的 ImageNet 图像识别挑战赛中大放异彩,吸收了 NiN 中网络串联网络的思想,并做了很大改进,这里我们介绍第一个版本。
GoogLeNet 一度是 ImageNet 上最高效的模型之一,可以用更少的计算量达到同样的准确率。至于具体的通道数分配,要在 ImageNet 上大量实验得到(所以还是大力出奇迹)
GoogLeNet 中的基础卷积块叫做 Inception,结构如下图所示:
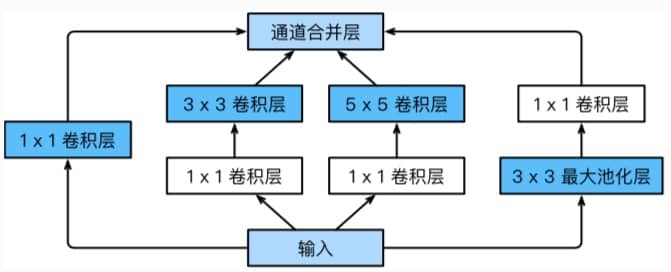
可以看到一个 Inception 块中有 4 条并行的线路,我们可以自定义每层输出的通道数,借此来控制模型复杂度。具体代码如下:
注:卷积部分使用了 5 个 block,每个 block 之间使用 stride 2 的 3x3 最大池化层来减小输出宽度
Batch Normalization
Batch Normalization 可以让较深的神经网络训练变得更加容易。在模型训练时,Batch Normalization 利用小批量上的均值和标准差,不断调整神经网络中间输出,从而使整个神经网络在各层中间输出的数值更稳定,也使得我们可以训练和设计更深的网络。
- 全连接层:在进入激活函数前进行归一化
- 卷积层:进入激活函数之前进行归一化,不同的通道分别做归一化,每个通道有独立的拉伸和偏移参数
同样我们有自己实现和借助框架两种方式,代码如下:
ResNet
理论上来说,我们不断添加层,模型精度应该越来越高,但是实际情况并非如此,甚至可能变得更差了。为了解决这个问题,何恺明等人提出了残差网络 ResNet,夺得了 2015 年 ImageNet 冠军。(题外话:通过看到前面这一系列模型,一个影响广泛的比赛,会对领域发展起到非常大的助推作用)
我们先来看看残差块的设计:

- 左图:输入 x,希望虚线部分能够学习出 f(x)
- 右图:输入 x,希望虚线部分能够学习出 f(x) - x,更容易学习,x 也可以通过跨层的数据线路更快向前传播
这个思路非常深刻影响了未来的神经网络设计,为了能够让 f(x)-x 和 x 相加,可能需要引入 1x1 的卷积层来变化尺寸。具体代码如下;
DenseNet
DenseNet 可以看作是 ResNet 的发展创新,对比如下:
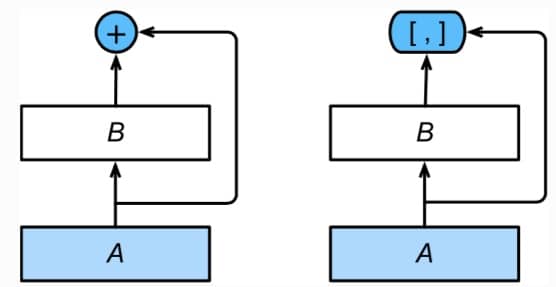
- 左边:ResNet,A 的输出和 B 的输出相加(这就需要维度一致)
- 右边:DenseNet,A 的输出和 B 的输出拼起来
DenseNet 主要通过 dense block(确定输入和输入如何连接)和 transititon layer(控制通道数量)构成。具体的代码如下:
注:这一节代码量巨大,所以重点关注代码。