这一节我们来了解一些自然语言处理常用的技术,包括词嵌入、情感分类、机器翻译等,本节最好使用 GPU。
更新历史
- 2019.11.14: 完成初稿
Word2Vec
Word2Vec 的理解推荐这篇文章,对于工程角度来说,我们需要知道的是如何降低计算开销,主要的方法如下:
- 负采样通过考虑同时含有正样本和负样本的相互独立事件来构造损失函数。其训练中每一步的梯度计算开销与采样的噪声词的个数线性相关
- 层序 softmax 使用了二叉树,并根据根节点到叶节点的路径来构造损失函数,其训练中的每一步的梯度计算开销与词典大小的对数相关。
我们直接用 skip-gram 和负采样来实现一个 word2vec,使用的数据集是 PTB(Penn Tree Bank),代码如下:
另外,fastText 可以把构词信息引入 word2vec 中,虽然可以处理生僻词甚至词典中没有的单词,但是计算复杂度较高。
在有些情况下,交叉熵损失函数效果不佳,这时候就可以考虑平方损失,GloVe 就是这样的方法。
求近义词和类比词
在大规模语料上预训练的词向量常常可以用到下游自然语言处理任务中,这一节我们就用这个方式,通过词向量的余弦相似度,来寻找近义词和类比词。具体代码如下:
情感分析
情感分析一般可以用 RNN 和 CNN,这里分别尝试一下。注意,这一节很需要 GPU。我们使用斯坦福 IMDb 数据集,具体代码如下:
其中 CNN 的部分用一维卷积来表征时序数据,另外使用时序最大池化层来处理时序数据。
机器翻译
机器翻译涉及到的要点是 Seq2Seq, Beam Search 和注意力机制,这里简单分别介绍下,感兴趣的同学,网上有很多相关介绍,我就不赘述了。
Seq2Seq 结构如下,实际上就是俩连在一起的 RNN。
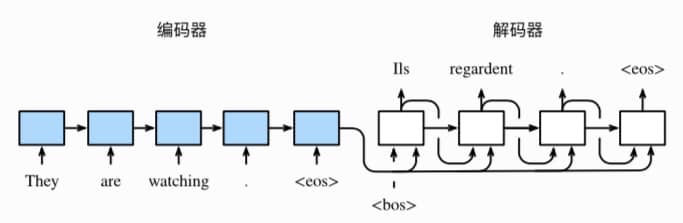
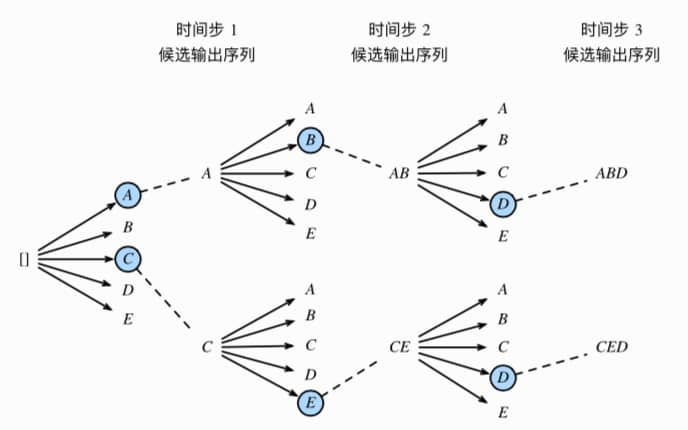
Beam Search 方式如下,简单来说就是在限制搜索成本的前提下,尽可能找到最有可能的组合。
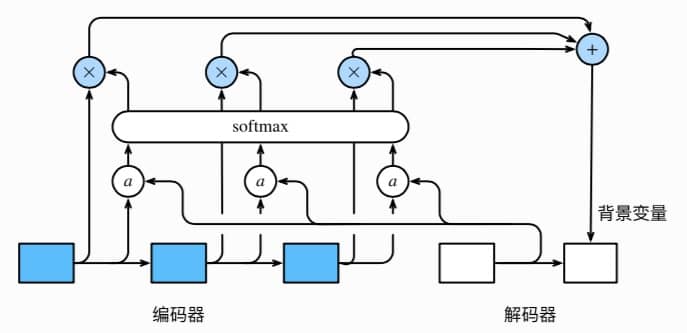
注意力机制通过对编码器所有时间步的隐藏状态做加权平均来得到背景变量。解码器在每一时间步调整这些权重,即注意力权重,从而能够在不同时间步分别关注输入序列中不同部分并编码进相应时间步的背景变量。原理如下:
具体的机器翻译的例子代码如下: