前面我们了解了什么是深度学习,万丈高楼平地起,我们先来学习一些基础知识
更新历史
- 2019.10.12: 完成初稿
二分类 Binary Classification
二分类的定义非常简单,就是要么是 1,要么是 0。我们在训练一个分类器的时候,不会用 for 循环,而是直接把训练数据拼接成 X 和 Y 两个矩阵,这样可以加快计算。
逻辑回归 Logistic Regression
对于二分类的问题,最常用的方法就是逻辑回归,它可以给出 0 到 1 之间的概率值,帮助我们做判断,具体的形式如下:
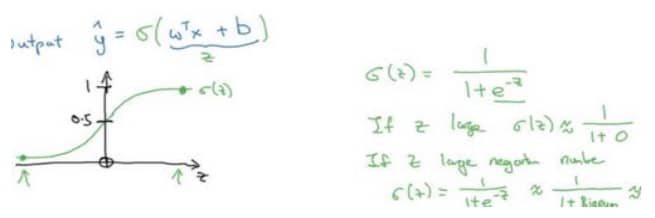
为了强调其重要性,我再打一次公式本身:
我们要做的就是通过训练数据,得到最佳的 w 和 b,接下来会说明如何得到这俩参数值。
代价函数 Cost Function
要了解代价函数,我们先要看看损失函数 Loss Function,简单粗暴一点理解,就是通过寻找损失函数的极值,我们可以找到最优的参数值 w 和 b。公式为:
这里 y 是真实的值,$\hat{y}$ 是我们预测的值,这样一个损失函数的意思就是当 y 为 0 的时候 $\hat{y}$ 要尽量接近 0;当 y 为 1 的时候 $\hat{y}$ 要尽量接近 1。为什么是这样,大家可以把 y = 0 或 1 带入到上面的公式中,就可以明白。
现在我们有了损失函数,对应的代价函数就是对 m 个样本的损失函数求和再除以 m,也就是求一个平均数,公式为
梯度下降 Gradient Descent
我们来梳理一下,首先我们有逻辑回归的函数:
为了求这个逻辑回归中的参数,我们需要最小化它的代价函数:
那么如果做这个最小化的操作,就需要梯度下降法。梯度下降法不是万能的,需要代价函数是一个凸函数。列举几个关键词:凸优化、拉格朗日乘子法、KKT 条件(这里不展开说明,感兴趣的同学可以自行探索)
假设代价函数只有一个参数 w,那么我们要做的就是不断进行下面的操作:
这里 $\alpha$ 表示学习率,后面的部分是 J(w) 对 w 的求导,符号是 d,如果参数是 w 和 b 两个,那么就是对 w 求偏导数,符号为 $\partial$。
导数 Derivatives
微积分相关内容大家可以搜索“微积分总结”,我就不再重复一次了。核心要点其实是俩:
- 导数就是斜率,只是有些是二维空间的,有些是高维空间的,代表某个点变化的趋势,我们可以利用这些趋势当做方向
- 大部分常用的函数对应的导数网上都可以查到
计算图 Computation Graph
简单理解,就是把一个函数的计算,分步骤用图的方式表示出来,比如我要计算 J(a,b,c) 的值,可以这样算:
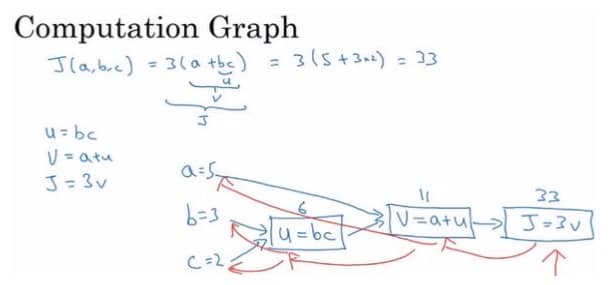
注:蓝线是计算 J 值的过程,红线是计算导数的过程,这俩就是前向传播和后向传播。
计算图求导 Derivatives with a Computation Graph
这一部分就是重点了,这里我们要记得的关键是:链式法则。接下来简单讲解下:
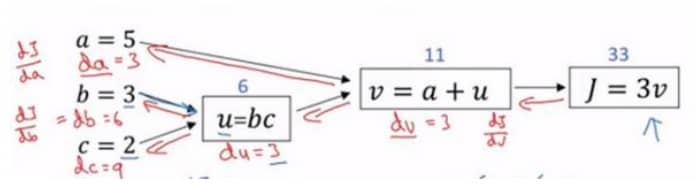
上图是和上一节一样的计算图,根据链式法则,我们来计算下面几个公式:
$\frac{dJ}{dv}$ 比较简单,直接求导可以得到结果为 3,同理我们可以得到 $\frac{dv}{du}=1$ 和 $\frac{dv}{da}=1$。于是我们可以得到
假设我们在编码,我们可以记为 dv = 3
假设我们在编码,我们可以记为 du = 3
假设我们在编码,我们可以记为 da = 3
最后我们来看看 $\frac{dJ}{db}$ 的计算,$\frac{dJ}{du}$ 前面我们记录了为 du = 3,所以关键在于 $\frac{du}{db}$,求导可得 $\frac{du}{db} = c= 2$,所以
假设我们在编码,我们可以记为 db = 6,同理我们可以得到 dc = 3*3 = 9
简单来说,就是一层一层倒着算,就可以得到对应的导数
逻辑回归梯度下降 Logistic Regression Gradient Descent
这一节我们把前面所学的各个要点组合起来:

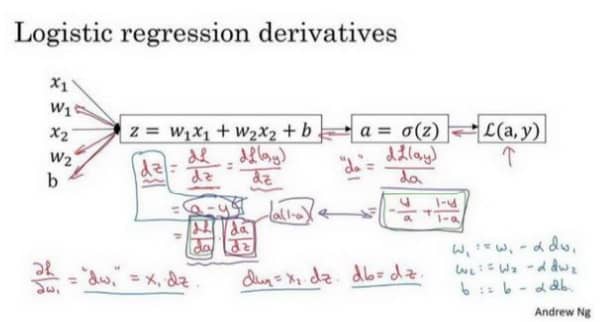
结论就是在编码中
dz = a - ydw1 = x1 * dzdw2 = x2 * dzdb = dz
更新的时候
w1 = w1 - a * dw1w2 = w2 - a * dw2b = b - a * db
实际训练时,我们可能一批批来进行训练,那么 m 个样本梯度下降(Gradient Descent on m Examples)就很有必要了解
简单来说就是求出这 m 个样本的梯度,然后求平均,最后更新 w 和 b 的值。
向量化 Vectorization
想要代码里不带 for,向量化不能错过!简单来说,向量化就是利用矩阵的能力,快速进行大量计算,这里我们用 Numpy 来做一个测试,具体的代码参考 1_vectorization_camparison.py
运行一下,结果是
1 | ❯ python 1_vectorization_camparison.py |
可以看到结果在小数点后 7 位都是一致的,但是向量化的版本比用 for 循环,快了 380 多倍!
逻辑回归向量化 Vectorizing Logistic Regression
利用好矩阵乘法,我们把要计算的内容放到对应矩阵中,就可以极大提高效果:
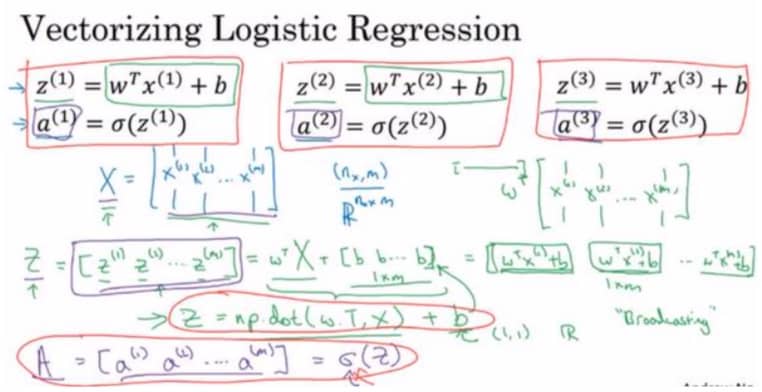
对应的 numpy 语句为 Z = np.dot(w.T, X) + b,注意,这里对于 b 这个变量,python 会通过广播(broadcasting) 操作扩展为 1*m 的行向量。
逻辑回归梯度向量化 Vectorizing Logistic Regression’s Gradient
经过一波公式代换,我们可以得到下面一组公式:
上面五个公式我们实现了前向和后向传播,即对所有训练样本实现了预测和求导。
然后我们用上面两个公式梯度下降更新参数
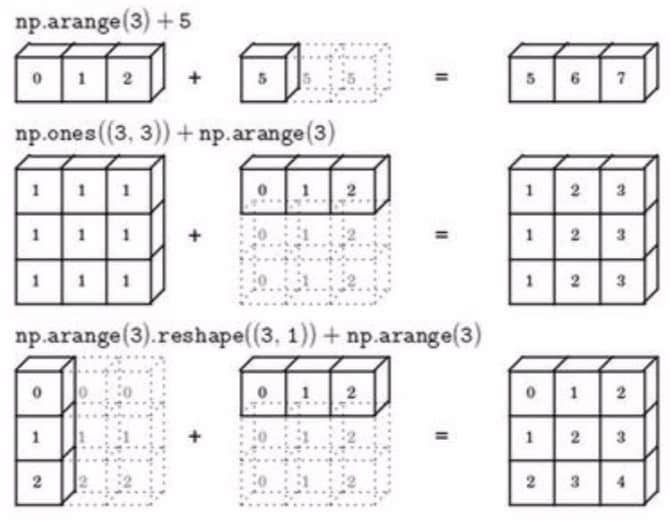
广播 Broadcasting
广播的机制可以用下图来总结,具体的还是需要大家自己体验一下:
编写 Python 代码的技巧
np.random.randn(5)= 一个 shape 为(5,)的结果,不是行向量,也不是列向量,称为一位数组,我们尽量不要这样用np.random.randn(5,1)= 一个 shape 为(5,1)的列向量 column vector(一个 5 行 1 列向量)np.random.randn(1,5)= 一个 shape 为(1,5)的行向量 row vector(一个 5 列 1 行向量)- 如果不确定一个向量的维度,就先放到 assert 语句中
- 如果你得到了一个一维数组,使用 reshape 方法转成行向量或列向量