作为 CNN 的最后一讲,我们来看看人脸识别和神经风格转化这两个有有趣的应用。
更新历史
- 2019.10.22: 完成初稿
人脸识别 Face Recognition
人脸识别随着 FaceID 和各种人脸解锁手机的出现大家应该已经不陌生,严格意义上来说,手机上的应用属于人脸验证(Face Verification),就是输入一张图片和某人的 ID,系统要验证是不是相符。
人脸验证的难点在于要解决“一次学”(one-shot learning) 问题,而人脸识别的难点在于准确率要非常高
One-Shot 学习
所谓 One-Shot 学习,就是要通过一张图片就学会识别一个人,而且我们输出的结果并不是具体某个分类,而是相似度(因为如果我们用 softmax 做 N 类分类,这几天来了新人,就需要变成 N+1 分类,但显然是不会重新训练模型的)。所以如果我们输入两张图片,这两张图片相似度很高,我们就认为是同一个人。
那么如何用神经网络学习这个相似度函数呢?
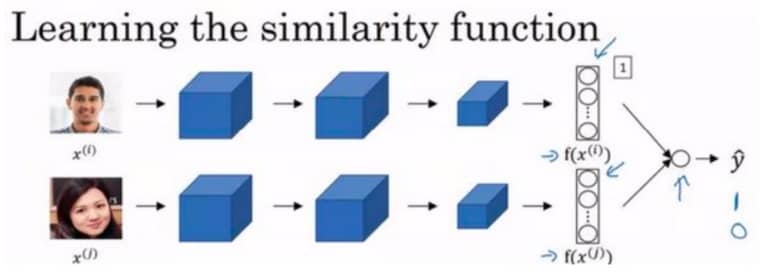
Siamese 网络
简单理解就是我们不用最终的分类结果,而用最后一层全连接的输出作为图像的 embedding,于是就可以进行比较:

那么问题来了,如何训练这个网络呢,简单来说就是让同一个人的两张图片编码接近,而不同人的编码相差较大。为了达到这个目的,我们需要引入三元组损失函数。
Triplet 损失
之所以叫三元组损失,因为我们需要同时看三张图片,分别称为 Anchor, Positive 和 Negative,简写为 A, P, N。它们间的关系应该满足:
实际使用时还需要对函数做一些变化,如下图所示:

我们的损失函数是:
我们在进行三元组选择的时候要尽量选择比较难的组合,网络才能真正学到东西。
面部验证与二分类 Face Verification and Binary Classification
除了通过 Triplet Loss 进行学习,我们还可以把人脸识别转化为一个二分类问题来进行学习,只要区分是不是同一个人即可,如下图所示:
神经风格转换 Neural Style Transfer
简单来说就是两张图片一张取其内容,另一张取其风格,然后合成一张图片,如下图所示:

要了解这其中的奥秘,先要了解卷积网络提取的特征有什么特点。
深度卷积网络学习 Deep ConvNets Learning
卷积网络的一个优势在于我们能够比较轻松地可视化每一层的结果(遍历训练集,找到那些使单元激活最大化的图片块)。我们用下面这个卷积神经网络来做一个示范:
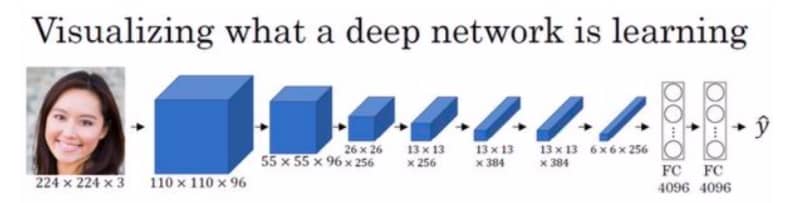
我们先来看看哪些图片能够最大程度激活第一层的隐藏单元:

我们可以看到,第一层找到的通常是比较简单的特征,比如边缘或颜色。继续把后面几层都这样处理的话,可以得到下面的结果:

总结一下,就是随着网络越来越深,能够识别的物体也越来越复杂。
代价函数 Cost Function
还是之前的三张图片,我们现在需要通过代价函数,来告诉神经网络如何进行优化。

原来只有一个公式的代价函数已经不适用了,我们的代价函数会包括内容代价和风格代价,公式为:
训练过程也很简单,我们要做的就是随机生成初始图像 G,然后放到代价函数中进行优化,图像 G 本身可以理解为需要优化的参数,只是我们会再对其进行可视化操作。优化的过程如下图所示:

内容代价函数 Content Cost Function
内容部分我们一般会选择网络的中间层,记为 l。我们可以用 VGG 网络或是其他类型的预训练模型,目标就是获得第 l 层的输出。于是内容损失函数为:
这里我们假设损失较小的时候,即为内容相似。
风格代价函数 Style Cost Function
图片的风格听起来有点玄,我们来看下面的例子:
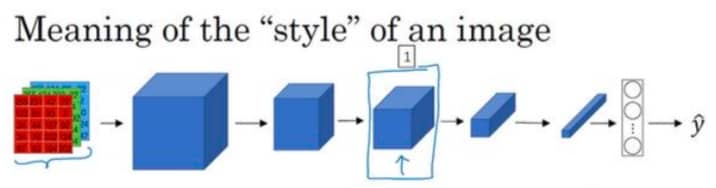
假设我们用箭头所指的那一层来衡量风格,定义为这一层中各个通道之间激活项的相关系数。
这个概念从公式上看比较复杂,这里简单以直观的角度解释下:我们知道卷积神经网络中的每层是由多个通道组成,而这些不同的通道关注图片不同的特点,有的关注纹理,有的关注颜色,而这些特点有的相关,有的不相关。正是这些相关与不相关的特点,实际上表征了图像的风格。比如某一张图片的通道显示其中两个很相关的是红色配直角,另一张是红色配曲线,那么同样是红色,但是相关的特征不同,这两张图片的风格就不太一样。所以,我们通过计算通道间的相关系数,就可以得到图片风格,继而完成我们的风格损失函数:

有了内容和风格代价函数,我们就可以训练出一张精美的图片了。