第一课我们来学习一些有关深度学习的基础知识,方便后面的深入学习。
更新历史
- 2019.11.06: 完成初稿
PyTorch 中的 Tensor
具体的操作参考 1_tensor_basic.py,一些要点如下:
- 使用索引取出的内容与原数据共享内存,修改一个,另一个也会变化
- 用
view()来改变 Tensor 的形状 - 如果要深拷贝,需要先
clone,然后再使用view改变形状。这样做的另一个好处是拷贝操作会被记录在计算图中,梯度回传的时候,源 Tensor 也可以进行更新 - 用
item()将 Tensor 转为 Python 数字 - Tensor 支持广播机制
- 索引和
view不会开辟新内存,但是y = x + y会开辟 numpy()和from_numpy()做数组相互转换的时候,共享内存,一个修改,另一个也会改变,如果用torch.tensor(),则会进行数据拷贝(所有在 CPU 上的 Tensor 都支持与 Numpy 相互转换,CharTensor 除外)
线性回归
线性回归的输出是一个连续值,适用于回归问题,比如我们要预测一个具体的数值,就可以用线性回归。如果想要预测某个类别,我们可以使用 softmax 回归。而线性回归和 softmax 回归都可以用单层神经网络完成,我们来看一下。
一般来说,我们在进行模型训练时,不会出现 for 这个关键词,而采用向量化技术来加速,具体的代码参考 2_vector_speed.py
线性回归的理论公式这里不再赘述,我们用复杂和简单的方法分别实现下线性回归,代码如下:
Softmax 回归
与线性回归不同,我们的输出单元从 1 个变成了 N 个(N 就是要进行区分的类别数量),其中每个都输出对应类别可能的概率,这样我们找到概率最大的,就知道是哪一类了。
因为我们输出不是一个值,为了更好衡量损失,我们一般使用交叉熵损失函数。而在具体评价模型效果的时候,我们通常用 Accuracy 来评价,就是正确预测数量与总预测数量的比值。
和上一小节一样,我们依然会用复杂和简单的方法实现 Softmax 回归,代码如下:
这里我们可以了解深度学习模型的基本套路:获取数据、读取数据、定义模型和损失函数,确定优化算法,然后执行训练、预测。
多层感知机
前面无论是线性回归还是 Softmax 回归都是单层神经网络,这里我们通过多层感知机 MLP 来学习多层神经网络。
同样的我们依然有两种实现方式,代码如下:
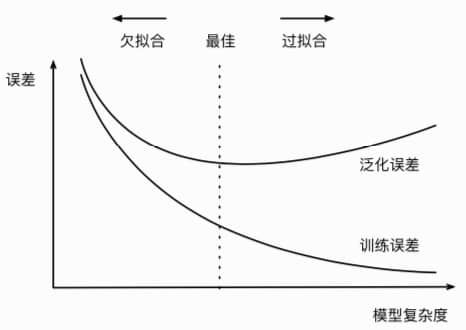
模型选择、欠拟合和过拟合
我们看看刚才的执行结果,可以发现训练集的准确率一般要比测试集高。这是为什么呢?
1 | ❯ python 8_mlp_torch.py |
简单来说,训练集可以看作是你做五年高考三年模拟的成绩,而测试集则是真正参加高考,那么一般来说高考成绩就不如模拟题成绩高(当然有人会超常发挥,但是这里只是一个简单类比)。
我们要关注的是如何降低泛化误差,也就是努力提高测试集甚至更广泛的验证时的准确率。这里可以引入验证数据集或 K-Fold 交叉验证等技术,来充分利用好数据。
模型复杂度与拟合程度的关系如下,我们就是通过各种指标,尽量找到最佳点:
权重衰减
模型的训练误差远小于测试误差,一般来说就是出现了过拟合,为了应对过拟合,我们可以使用权重衰减(weight decay)。权重衰减等价于 L2 正则化。
这里我们用高维线性回归来做例子,维度为 200。而生成样本标签的公式如下:
同样的我们依然有两种实现方式,代码如下:
Dropout
另一种抑制过拟合的方式是 dropout,这里我们指的是 inverted dropout。注意,我们只在训练的时候使用 dropout,测试的时候不用。
同样的我们依然有两种实现方式,代码如下:
注:关于神经网络的正向、反向传播,计算图等概念,请自行了解。
房价预测实战
这本书很好的地方就是还带有一个实战例子,通过实战学习深度学习,是比较有效率的方法。更重要的是,通过实战,可以发现现实世界有很多意想不到的困难在等着我们,比如脏数据等等。
不废话,上代码,数据集如果没有办法注册 kaggle,可以轻松在国内找到。代码如下: