从这节课开始,我们来学习另一类非常出名的神经网络结构 —— RNN(Recurrent Neural Networks)。
更新历史
- 2019.10.23: 完成初稿
序列模型 Sequence Model
循环神经网络在语音识别、自然语言处理中有着非常好的表现,下面这些领域都使用了 RNN:
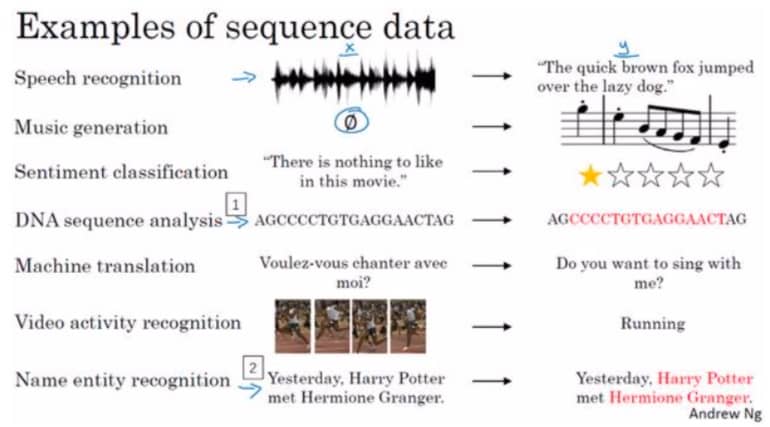
Awesome!接下来让我们从数学符号开始,走进科学,走进 RNN
数学符号 Notation
我们看下面这个例子:
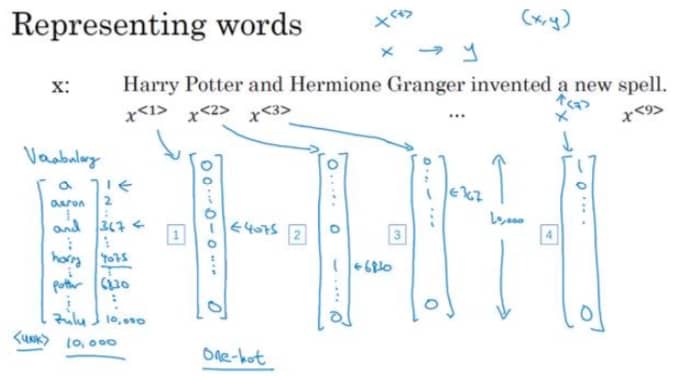
针对 NLP,我们一般会有一个词表,就是从单词到编码的映射。有了词表之后,我们就可以把每个单词记为一个向量,这个向量的长度就是词表的长度,而对应单词的编码位置的值为 1,其他为 0(这就是 one-hot 编码)。如果遇到不在词表中的词,那么统一标记为
现在我们有了 X,接下来看看 Y,也就是我们希望模型输出什么样的结果,如下图所示:

这里的模型主要用于检测人名,我们希望人名对应的单词输出 1,否则输出 0。现在我们有了 X 和 Y,就要看看中间的神经网络模型要如何设计了。
循环神经网络模型 Recurrent Neural Network Model
前面提到,我们的目标就是用神经网络来找到 X 和 Y 的映射,那么标准的神经网络是不是也可以完成这个目标?我们来试试看:
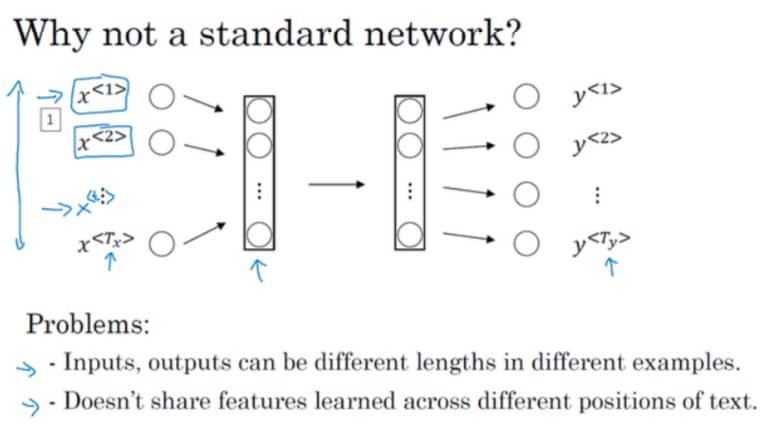
结论是不合适,所以我们再来看看 RNN 是如何处理的:

循环神经网络是从左向右扫描数据的,同时每个时间步的参数也是共享的,并且在每一步的预测时,还会利用到前面的节点的输出(当然我们也可以利用后面的节点,用双向循环神经网络 BRNN)。
RNN 的前向传播如下:
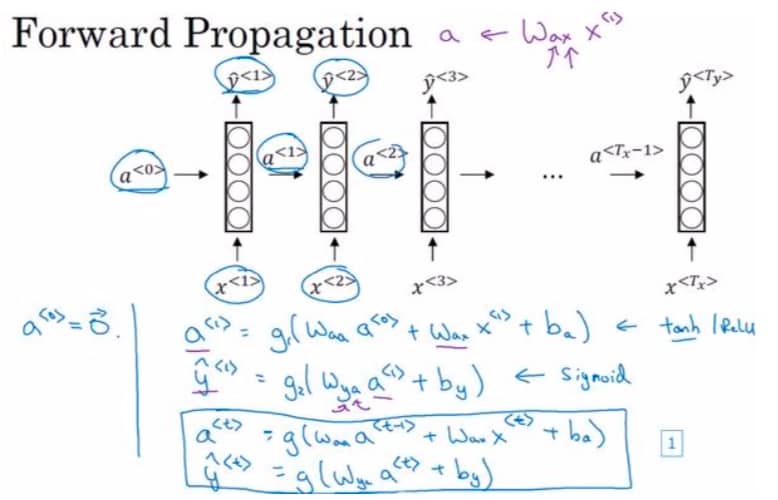
这里的关键就是 $W{aa}, W{ax}$ 这两个权重矩阵。
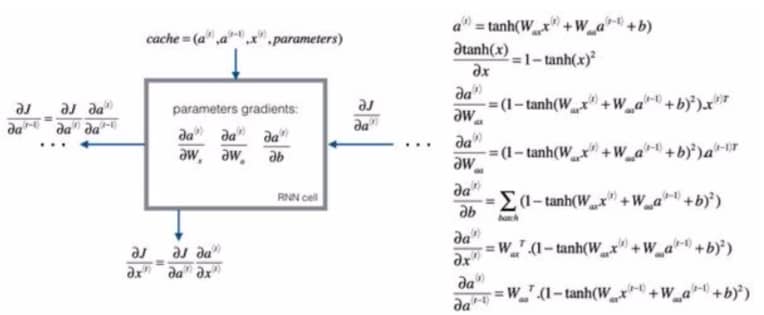
时间上的反向传播 Backpropagation Through Time
一般来说如果用框架来编程,反向传播会自动处理好,不过我们也简单了解下:

RNN 反向传播示意图:
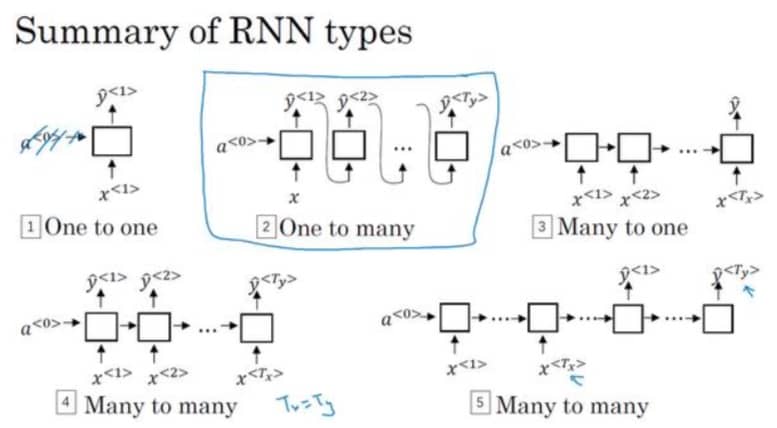
不同类型的 RNN
前面我们看到的 RNN 例子,X 中有多少个元素,Y 也有相同的个数,但这并不是绝对的,如下图所示:

总结下主要有下面几种类型:
语言模型和序列生成 Language Model and Sequence Generation
语言模型做的事情就是告诉你某个特定句子出现的概率是多少。下图是一个 RNN 模型:
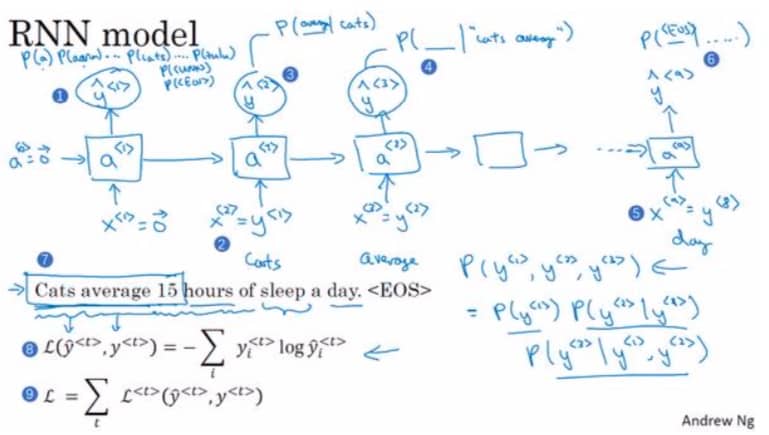
这里我们重点关注下损失函数,实际上的操作是把所有单个预测的损失函数都加起来。
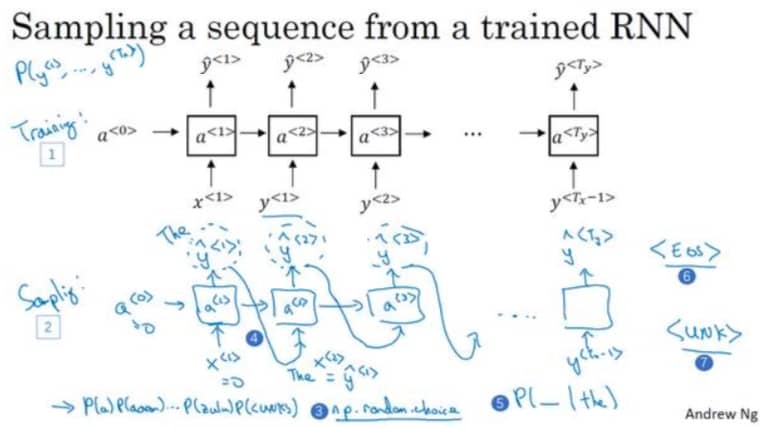
新序列采样 Sampling Novel Sequences
假设我们学习了一个语言模型,想要看看它到底学会了什么,最简单的办法就是试一下,比如输入第一个单词 The,然后网络会输出另外一个单词 A,我们再把单词 A 放到网络中,直到最终网络输出句子结束,如下图所示:
除了基于单词的语言模型,还有一种基于字符的,如下图所示:
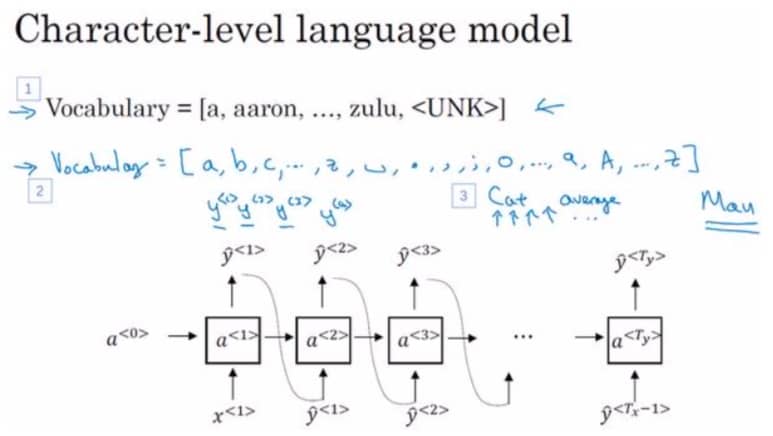
这种情况下,我们的字典只要包含 26 个字母,10 个阿拉伯数字,还有空格就可以,不会出现 UNK 问题。不过用字符的问题在于序列长度会增加数倍,训练起来需要耗费更大的计算力。
RNN 的一个缺点在于不擅长处理长期依赖的问题,因为随着序列长度的增加,往往会出现梯度消失或梯度爆炸这样的问题(比如一个 )。我们可以使用 GRU 来解决这个问题。
GRU 单元
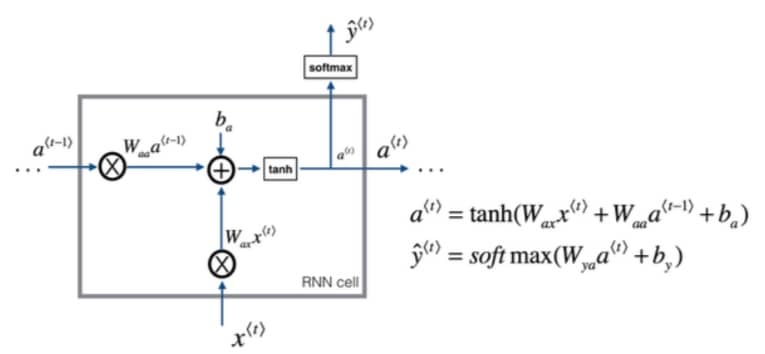
GRU 改变了 RNN 的隐藏层,使其可以更好地捕捉深层连接,并改善了梯度消失问题,我们先来回顾下 RNN 单元,左图相当于是右边公式的可视化:
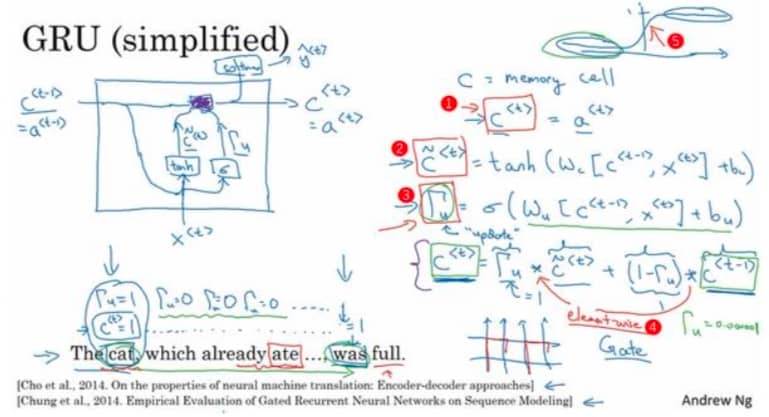
假设我们输入的序列是 The cat, which already ate …, was full. 我们需要网络能够关注 cat 和 was,这样就不会错误使用 were。因为 RNN 无法很好处理这样一前一后的依赖,GRU 单元中增加了一个新的变量 c,称为记忆细胞,在时间 t,记忆细胞的激活值 $c^{
简单来说就是通过一个新的参数来记忆额外的东西,如果觉得公式比较复杂,也不用担心,因为大部分深度学习框架都已经实现好了(也侧面说明 GRU 多么经典)。
LSTM 单元
LSTM 可以看作是 GRU 更复杂一点的版本,公式上对比如下:

用图片画出来就是:
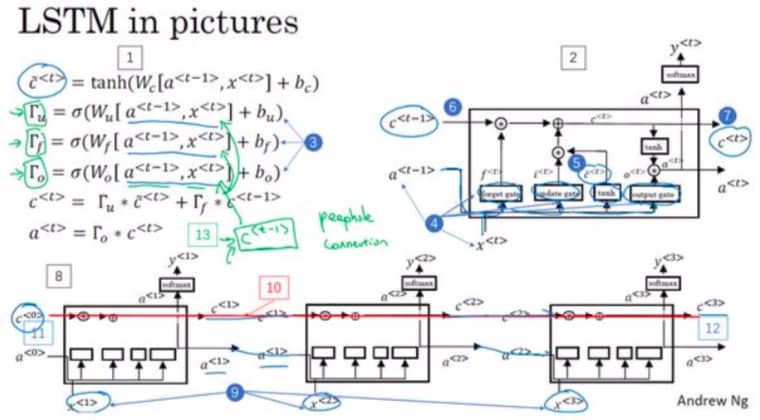
如果觉得比较复杂,也不要紧,只要大概知道 GRU 和 LSTM 的差别即可。
虽然我们先介绍了 GRU,但其实在历史上 LSTM 最先出现,GRU 则是最近才出现的。GRU 的优点在于简单,因此可以创建更大的模型,而且只有两个门,计算速度更快。LSTM 则更为强大和灵活,因为有三个门。一般来说可以先尝试 LSTM,然后再看看 GRU。
双向循环神经网络 Bidirectional RNN
单向 RNN 是从第一个词计算到最后一个词,而双向 RNN 增加的方向就是从最后一个词到第一个词,相当于计算两遍,算完之后就可以计算预测结果了,如下图所示:
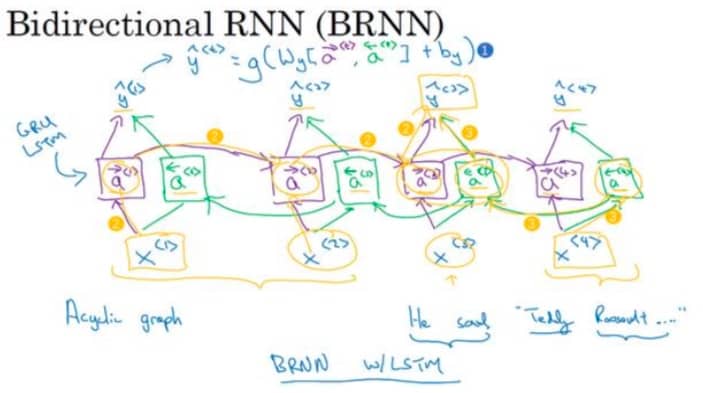
注意,这里的单元可以是 RNN,也可以是 GRU 或 LSTM。对于自然语言处理来说,一般都会使用双向 LSTM。
深层循环神经网络 Deep RNNs
如果要学习非常复杂的函数,通常会把 RNN 的多个层堆叠在一起,如下图所示:
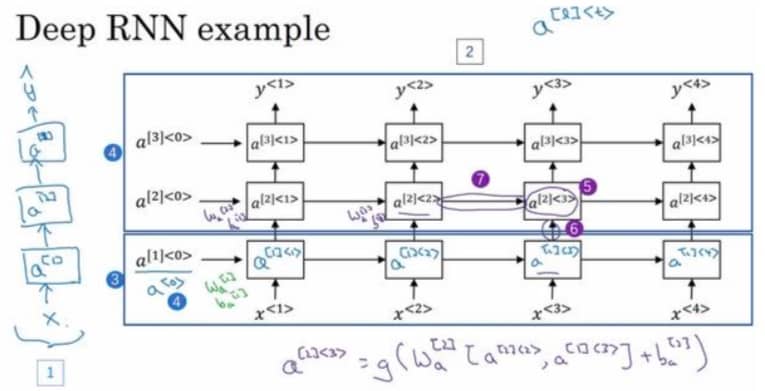
对于 RNN 来说,一般最多叠加 3 层,因为 3 还需要乘上时间维度,网络会变得非常大。